本文最后更新于:2024年10月1日 16:34
本节任务要点
任务要求 :基于 LlamaIndex 构建自己的 RAG 知识库,寻找一个问题 A 在使用 LlamaIndex 之前InternLM2-Chat-1.8B模型不会回答,借助 LlamaIndex 后 InternLM2-Chat-1.8B 模型具备回答 A 的能力,截图保存。
实践流程 新开一个30% A100机器 Cuda11.7-conda 镜像 不要选错/用之前的那个!!!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 conda create -n llamaindex python=3 .10 conda activate llamaindexconda install pytorch==2 .0 .1 torchvision==0 .15 .2 torchaudio==2 .0 .2 pytorch-cuda=11 .7 -c pytorch -c nvidiapip install einops==0 .7 .0 protobuf==5 .26 .1 pip install llama-index==0 .10 .38 pip install llama-index-llms-huggingface==0 .2 .0 pip install "transformers[torch]==4.41.1" pip install "huggingface_hub[inference]==0.23.1" pip install huggingface_hub==0 .23 .1 pip install sentence-transformers==2 .7 .0 pip install sentencepiece==0 .2 .0
1 2 3 4 5 6 7 8 9 10 11 12 13 14 // hf-mirror.com/paraphrase-multilingual-MiniLM-L12-v2 --local-dir / root/project/ rag/model/ sentence-transformer/root/ project/rag//gi tee.com/yzy0612/ nltk_data.git --branch gh-pages/* ./
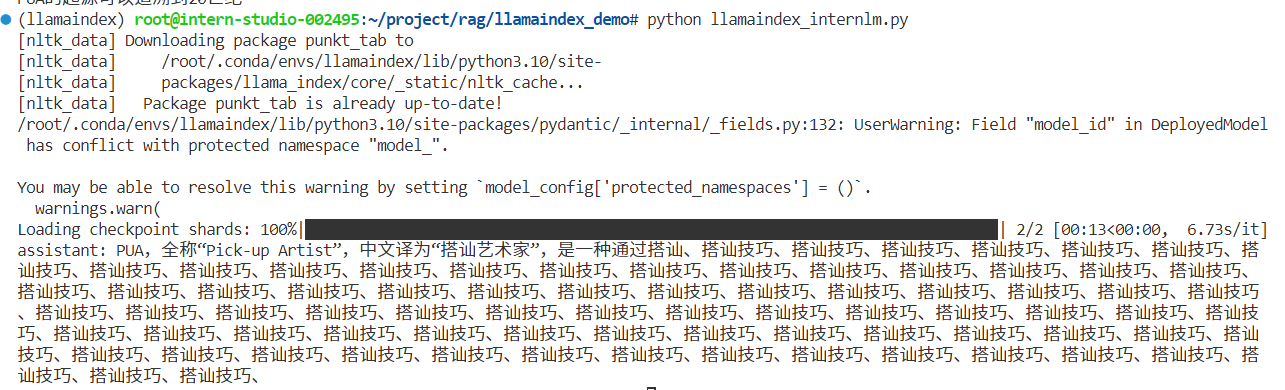
InternLM2 1.8B 配置 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 # 运行以下指令,把 InternLM2 1.8 B 软连接出来, 天才/root/ project /rag/m odel/root/ share/new_models/ Shanghai_AI_Laboratory/internlm2-chat-1_8b/ ./from llama_index.llms.huggingface import HuggingFaceLLMfrom llama_index.core.llms import ChatMessage"/root/project/rag/model/internlm2-chat-1_8b" ,"/root/project/rag/model/internlm2-chat-1_8b" ,"trust_remote_code" :True },"trust_remote_code" :True }"什么是PUA?" )])print (rsp)/root/ project /rag/ llamaindex_demo
虽然懂一点但不全面,而且停不下来了这哥们
安装 LlamaIndex RAG 1 2 3 4 5 6 7 8 pip install llama-index-embeddings-huggingface==0 .2 .0 llama-index-embeddings-instructor==0 .1 .3 cd ~/llamaindex_demomkdir datacd datagit clone https://github.com/InternLM/xtuner.gitmv xtuner/README_zh-CN.md ./
编辑 llamaindex_demo/llamaindex_RAG.py
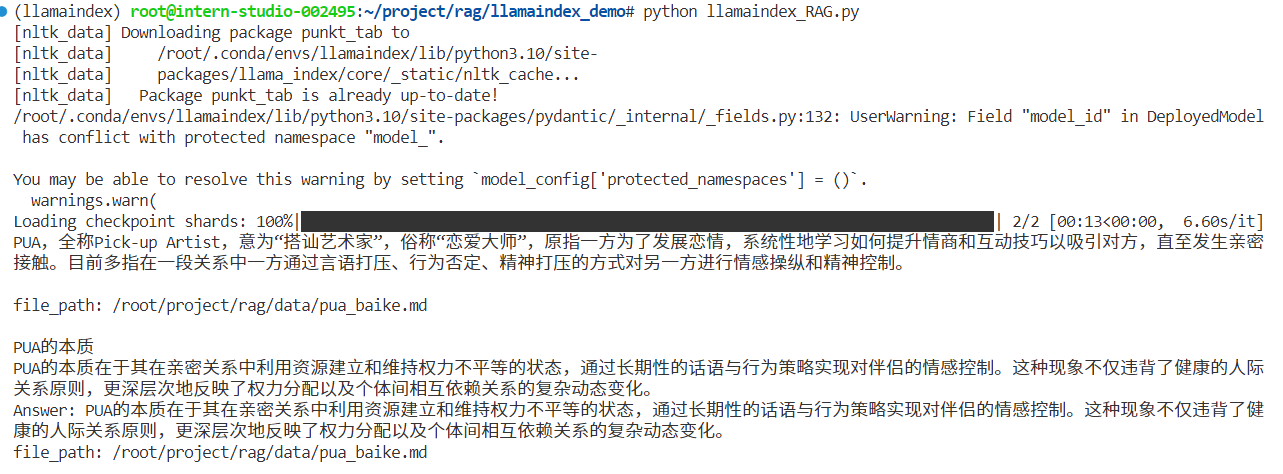
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settingsimport HuggingFaceEmbeddingimport HuggingFaceLLMembed_model = HuggingFaceEmbedding(model_name="/root/project/rag/model/sentence-transformer" embed_model = embed_modelllm = HuggingFaceLLM(model_name="/root/project/rag/model/internlm2-chat-1_8b", tokenizer_name="/root/project/rag/model/internlm2-chat-1_8b", model_kwargs={"trust_remote_code":True}, tokenizer_kwargs={"trust_remote_code":True} llm = llmdocuments = SimpleDirectoryReader("/root/llamaindex_demo/data" ).load_data()index = VectorStoreIndex.from_documents(documents)query_engine = index.as_query_engine()response = query_engine.query("啥是PUA?" )
执行结果
1 2 cd /root/ project /rag/ llamaindex_demo
这里找到了和PUA定义基本概念相关的内容切片,内容比较全面
LlamaIndex web 1 pip install streamlit==1 .36 .0
编辑 llamaindex_demo/app.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 import streamlit as st st .set_page_config(page_title="llama_index_demo" , page_icon="🦜🔗" )st .title("llama_index_demo" )"/root/project/rag/model/sentence-transformer" "/root/project/rag/model/internlm2-chat-1_8b" ,"/root/project/rag/model/internlm2-chat-1_8b" ,"trust_remote_code" : True},"trust_remote_code" : True}"/root/project/rag/data" ).load_data()index = VectorStoreIndex.from_documents(documents)index .as_query_engine()return query_engineif 'query_engine' not in st .session_state:st .session_state['query_engine' ] = init_models()st .session_state['query_engine' ].query(question)return responseif "messages" not in st .session_state.keys ():st .session_state.messages = [{"role" : "assistant" , "content" : "你好,我是你的助手,有什么我可以帮助你的吗?" }] or clear chat messages for message in st .session_state.messages: st .chat_message(message["role" ]):st .write (message["content" ])st .session_state.messages = [{"role" : "assistant" , "content" : "你好,我是你的助手,有什么我可以帮助你的吗?" }]st .sidebar.button('Clear Chat History' , on_click=clear_chat_history)for generating LLaMA2 responsereturn greet2(prompt_input)if prompt := st .chat_input():st .session_state.messages .append ({"role" : "user" , "content" : prompt})st .chat_message("user" ):st .write (prompt)last message is not from assistantif st .session_state.messages [-1 ]["role" ] != "assistant" :st .chat_message("assistant" ):st .spinner("Thinking..." ):st .empty ()"role" : "assistant" , "content" : response}st .session_state.messages .append (message)
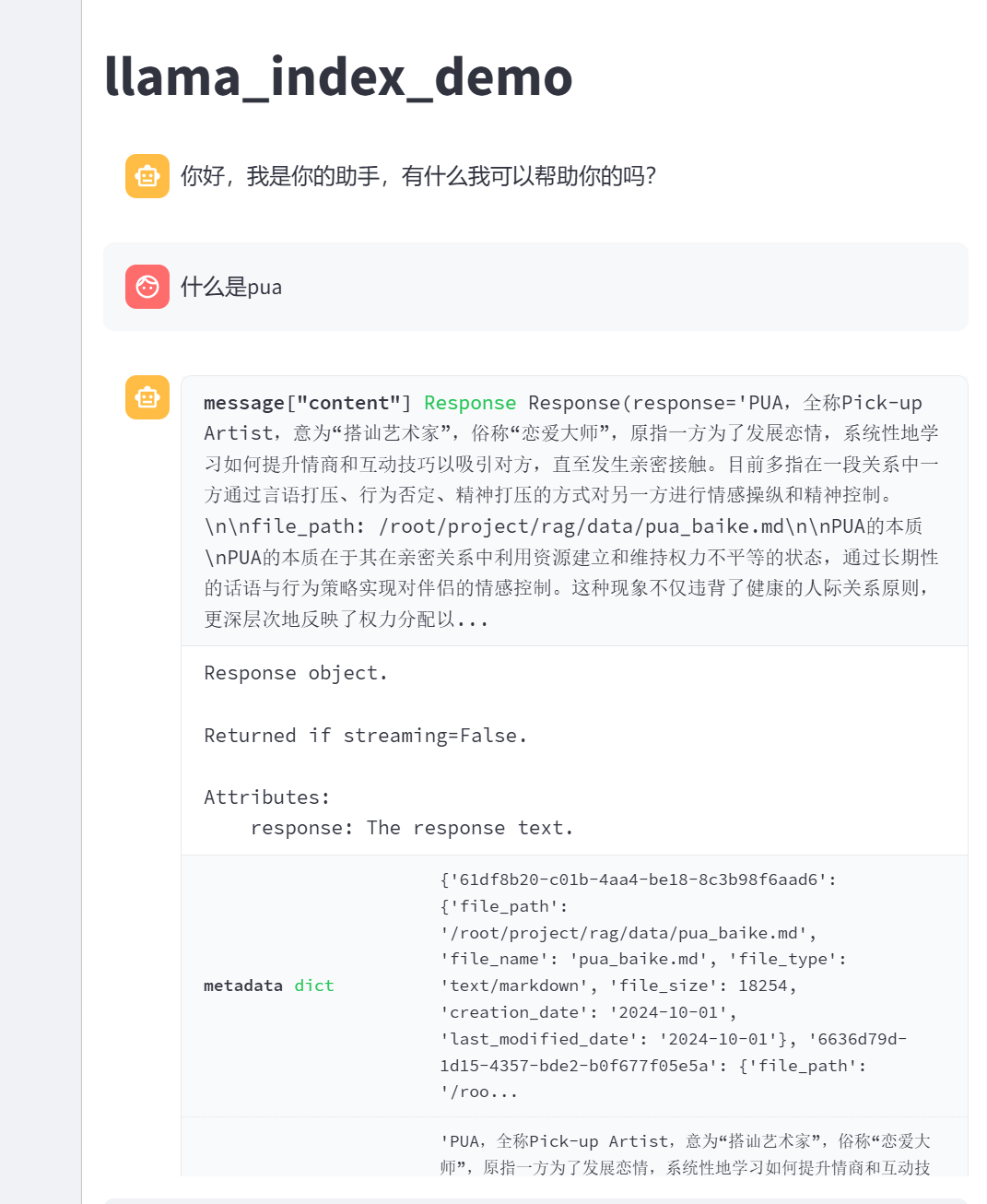
运行
执行结果
数据收集 收集关于PUA定义、危害、特点、不同场景、解决方案等相关资料
来源:百度百科:https://baike.baidu.com/item/PUA/5999185
总结
学会使用hf镜像下载文件,https://hf-mirror.com/
SimpleDirectoryReader 默认会尝试读取它找到的所有文件,将它们作为文本处理。它显式支持以下文件类型,这些类型会根据文件扩展名自动检测:.csv .docx .epub .ipynb .jpeg .jpg .md .mp3 .mp4 .pdf .png .ppt等
数据质量重要,学会洗数据