李宏毅机器学习 | Datawhale202208 组队学习
本文最后更新于:2022年9月13日 07:54
课程概述
注:
- 笔记基于Datawhale 202208的组队学习活动,参考李宏毅机器学习课程,对AI基础知识进行梳理,了解的事物不再做记录,仅作不了解的细节的补充。
- 李宏毅2021偏向深度学习,相对前沿一点的知识;2017/2019等偏向机器学习,经典的知识
- 李宏毅课程资料:太多了,可以去老师官网、油管也有视频,B站也有很多搬运视频,比如啥都会一点的研究生的(他的是两次课程合并了,我不太习惯,看自己情况),看Datawhale的分开的两次视频也行,同时Datawhale官网还提供了2017/2019版本的笔记便于快速过知识点。
- 其他的老师还有公司的资料也挺多的,以后有时间会对比不同课程(如李沐、吴恩达、还有飞桨平台的等等教程进行总结)。比如李沐老师的动手学深度学习有全书电子版网站,可以直接复制latex公式很方便。
第一章 机器学习介绍
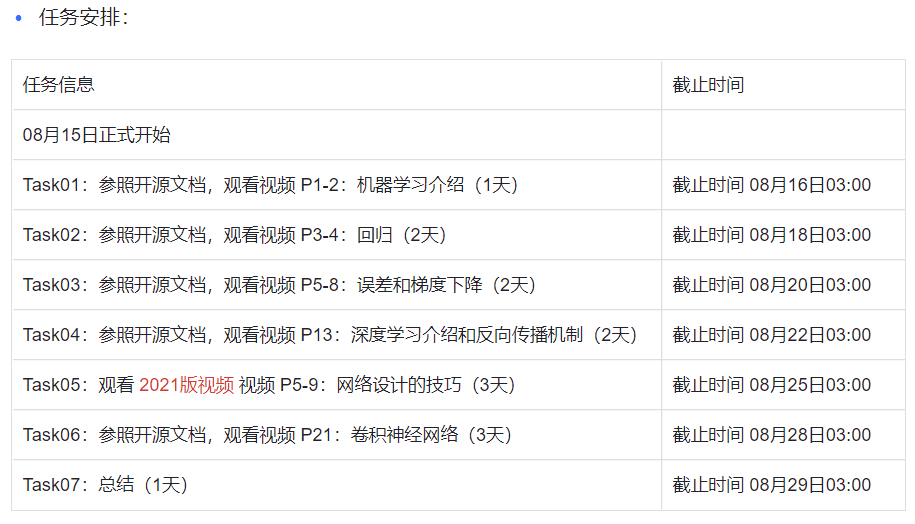
监督学习中的结构化学习:一般说ML是两大类的问题,regression和classification。其实还应该包括structure learning,举例:在语音辨识里面,机器输入是声音讯号,输出是一个句子。句子是要很多词汇拼凑完成。它是一个有结构性的object。或者是说在机器翻译里面你说一句话,你输入中文希望机器翻成英文,它的输出也是有结构性的。或者你今天要做的是人脸辨识,来给机器看张图片。然后机器要把这些东西标出来,这也是一个structure learning问题。
个人理解其实狭义ML就指的是分类和回归,主要针对的是结构化数据(表格数据)的处理。ML另一部分就是DL,DL包括上文所说的NLP、CV,其实本质也是转为了vector向量然后进行各种处理。总之认为ML主要是使用数学化的一些方法(随机森林等),DL需要搭建深度的网络结构。
第二章 为什么要学习机器学习
- 这章笑死了,直接朗读文本
- “我们知道要训练出厉害的AI,AI训练师功不可没”逗号直接读出来,没字读成mei2而不是mo4,这大概也是需要ML/AI的一个原因hhh
第三章 回归
构建模型基本步骤
- step1:模型假设,选择模型框架(线性模型等)
- step2:模型评估,如何判断众多模型的好坏(损失函数)
- step3:模型优化,如何筛选最优的模型(梯度下降)【应该理解为确定模型后如何让该模型尽早达到最优解,这包括调参(参数选择,优化方式选择)】
对于最基本的回归模型而言:
选择线性回归LR为model
选择均方误差MSE为loss
注:loss函数指单个样本的预测值和真值的偏差,cost函数指整体样本的预测值和真值的偏差
选择梯度下降GD为优化方式
问题:
- 问题1:当前最优(Stuck at local minima)
- 问题2:等于0(Stuck at saddle point)
- 问题3:趋近于0(Very slow at the plateau)
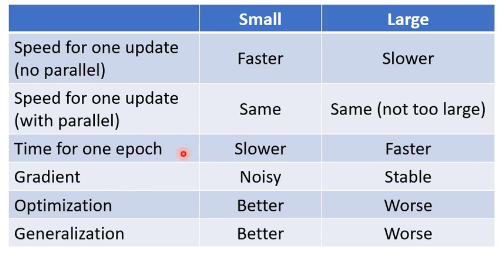
注:通常使用小批量随机梯度下降mini-batch SGD
线性回归解析解
- 高阶回归模型过拟合严重,需要权衡
- 优化:整合模型、增加数据、正则化
第五章 误差从哪里来
error = bias + variance
死去的概率论开始杀我,样本与总体的均值和方差
- 偏差大-欠拟合:重新设计模型
- 方差大-过拟合:更多的数据(含数据增强)等
- 偏差和方差之间需要权衡
- 常见误区:模型训练后直接在A榜提交,A榜分数高模型就好,其实在B榜会很拉(有时候还把A的数据合并到test算平均值什么的,算是数据穿越,应当避免)
- 考虑:从train训练集spilit出val验证集先进行预测,在此基础上延伸出K折交叉验证Kfold,Kfold也有很多种,比如StratifiedKFold可以按照label的比例进行分割,选择val上平均最好的模型
第六章 梯度下降
- 偏导
- 选择合适的学习率 $η>0$ 来生成典型的梯度下降算法:
自适应方法:随着次数的增加,通过一些因子来减少学习率
batch (Vanilla) gradient descent:每次计算在整个数据集上的梯度
- 学习率 $\eta^{t}=\frac{\eta}{\sqrt{t+1}}$
- 学习率每次对于每一个参数都是一样的
Adagrad 算法(别看成adam了)
提出背景:常见特征的参数相当迅速地收敛到最佳值,而对于不常见的特征,我们仍缺乏足够的观测以确定其最佳值。 换句话说,学习率要么对于常见特征而言降低太慢,要么对于不常见特征而言降低太快。
解决此问题的一个方法是记录我们看到特定特征的次数,然后将其用作调整学习率。 即我们可以使用大小为 $\eta_i = \frac{\eta_0}{\sqrt{s(i, t) + c}}$ 的学习率,而不是 $\eta = \frac{\eta_0}{\sqrt{t + c}}$。 在这里 $s(i, t)$ 计下了我们截至 $t$ 时观察到功能 $i$ 的次数。 这其实很容易实施且不产生额外损耗。
关键步骤:$\mathrm{w}^{\mathrm{t}+1} \leftarrow \mathrm{w}^{\mathrm{t}}-\frac{\eta^{\mathrm{t}}}{\sigma^{\mathrm{t}}} \mathrm{g}^{\mathrm{t}}$
步骤(按照坐标顺序应用,化简后),$\mathbf{s}_0 = \mathbf{0}$
最好的步伐应该是:一次微分/二次微分,在尽可能不增加过多运算的情况下模拟二次微分。(如果计算二次微分,在实际情况中可能会增加很多的时间消耗)
随机梯度下降SGD
- 此时不需要像之前那样对所有的数据进行处理,只需要计算某一个例子的损失函数,就可以赶紧update 梯度。
特征缩放
- 标准化的方法(minmax,正态 )
梯度下降的限制
容易陷入局部极值。还有可能卡在不是极值,但微分值是0的地方。还有可能实际中只是当微分值小于某一个数值就停下来了,但这里只是比较平缓,并不是极值点。
第十三章 深度学习简介
- 隐藏层本质:通过隐藏层进行特征转换。把隐藏层通过特征提取来替代原来的特征工程,这样在最后一个隐藏层输出的就是一组新的特征(相当于黑箱操作)而对于输出层,其实是把前面的隐藏层的输出当做输入(经过特征提取得到的一组最好的特征)然后通过一个多分类器(可以是softmax函数)得到最后的输出y。
第十四章 反向传播
- 我们的目标是要求计算$\frac{\partial z}{\partial w}$(Forward pass的部分)和计算$\frac{\partial l}{\partial z}$ ( Backward pass的部分 ),然后把$\frac{\partial z}{\partial w}$和$\frac{\partial l}{\partial z}$相乘,我们就可以得到$\frac{\partial l}{\partial w}$,所有我们就可以得到神经网络中所有的参数,然后用梯度下降就可以不断更新,得到损失最小的函数
- 反向传播其实就是为了简化求导过程,将递归计算导数转换为递推计算倒数,效率更高
Lecture 2: What to do if my network fails to train
局部最小值与鞍点
- Loacl Minima, Saddle Point
- 维度较高的情况下大部分遇到的都是鞍点
- 可以通过hessian矩阵、$\lambda$ 的正负判断点的类型
- 在Saddle Point的下降方法

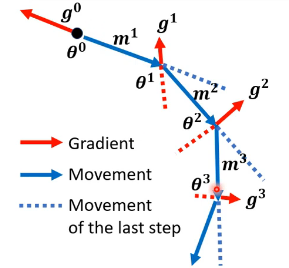
批次和动量
小批次和动量帮助避免陷入关键点
每一轮分批次的之前可以shuffle
比较
动量
李宏毅版本
李沐版本
自动调整学习率
AdaGrad (前面已介绍)
RMSProp
改进:Adagrad算法将梯度 $\mathbf{g}_t$ 的平方累加成状态矢量。因此,由于缺乏规范化,没有约束力,持续增长,几乎上是在算法收敛时呈线性递增。
Adam
$\beta_1 = 0.9, \beta_2 = 0.999, \mathbf{v}_0 = \mathbf{s}_0 = 0$
学习率调整
- 衰减
- warm up (可能的解释:在开始,simga的统计还不够精确)
损失函数
- MSE(回归)
- 交叉熵 Cross-entropy(分类)
批次标准化
batch normalization
由于在训练过程中,中间层的变化幅度不能过于剧烈,而批量规范化将每一层主动居中,并将它们重新调整为给定的平均值和大小
原因
- 数据预处理的方式通常会对最终结果产生巨大影响,它可以将参数的量级进行统一
- 对于典型的多层感知机或卷积神经网络,中间层中的变量可能具有更广的变化范围批量规范化的发明者非正式地假设,这些变量分布中的这种偏移可能会阻碍网络的收敛。我们可能会猜想,如果一个层的可变值是另一层的100倍,这可能需要对学习率进行补偿调整。
- 更深层的网络很复杂,容易过拟合。 这意味着正则化变得更加重要。
公式
ps:优化中的各种噪声源通常会导致更快的训练和较少的过拟合:这种变化似乎是正则化的一种形式。
争议:在提出批量规范化的论文中,作者解释了其原理:通过减少内部协变量偏移(internal covariate shift)。 据推测,作者所说的“内部协变量转移”类似于上述的投机直觉,即变量值的分布在训练过程中会发生变化。 然而,这种解释有两个问题: 1、这种偏移与严格定义的协变量偏移(covariate shift)非常不同,所以这个名字用词不当。 2、这种解释只提供了一种不明确的直觉,但留下了一个有待后续挖掘的问题:为什么这项技术如此有效?
test的batch normalization:使用移动加权平均迭代计算
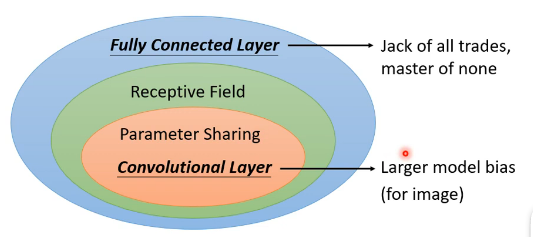
第二十一章 卷积神经网络
cnn能够有效的原理
- 一个神经元探测的是整的图片的一小部分(卷积)
- 不同的位置的同一个模式不需要不同类型的神经元(卷积)
- 下采样之后数据减少了但是对识别基本没有影响(池化)
属性参数:通道数、filter大小(长宽)、步长、填充padding
cnn基本架构:(卷积+池化)×n+展平+全连接网络
卷积和全连接的关系:拿掉了一些权重,不是全连接,是一种有规律的dropout,减少了需要的参数数量。如何减小:shared weight,一个filter滚动着进行计算,只需要filter尺寸大小的参数即可。
2021关系图
应用
- 图像处理(最多)
- 围棋:并没有用到pooling,每一个位置都用48个value来描述
- 语音:时频图,在语音上,我们通常只考虑在frequency方向上移动的filter
- 文字:nlp相关,word embedding,构建词向量。你把filter沿着句子里面词汇的顺序来移动,然后你就会得到一个vector。在文字处理上,filter只在时间的序列上移动(可以单向也可以双向,和时间有关,加入LSTM),不会在embedding 维度这个方向上移动。
DataWhale组队学习小结
- 关于学习:只学习了李宏毅机器学习的机器学习部分,对于2021新版的话后面深度学习的部分不在这次组队学习的学习范围内,首先是自己对机器学习的知识有了更深入的学习,不限于表面了,加深了对理论方法形成的过程的认知,以及记住了实现的公式。当然学习无止境,接下来自己会继续学习完剩余的章节,主动学习知识。
- 关于社区:第一次参加组队学习的活动hh,之前参加过一些DataWhale的教程内测活动,感觉挺不错的,是个很对新手很友好的社区,基本上理论、代码、实践竞赛都有涉及,大佬们也是很用心在经营社区,也有很多志同道合的同学在社区相互讨论交流,相互进步,希望DataWhale越来越好 ^ ^
Lecture 4: Sequence as input
- one-hot:看不出来距离
- word enbbedding:也是向量,但是相似词语距离相近
- output:n2n(词性标注),n21(正负情感分析),n2x(句子翻译)
- Self-attention:主要是,先考虑了整个句子vec2vec,然后fc,也有变式
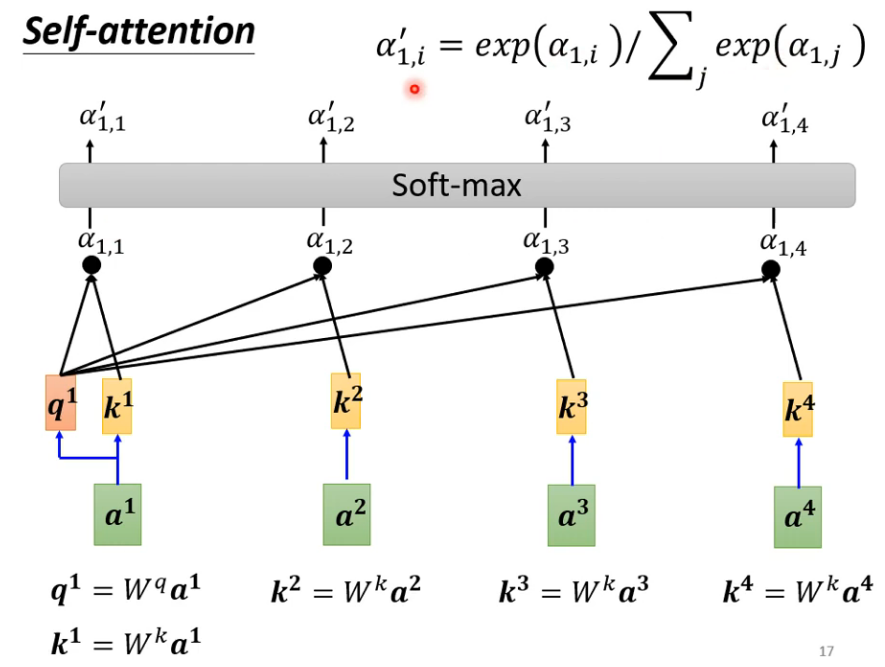
- 过程
- 在原向量列表中确定当前向量相关的向量距离(关联程度)
- dot-product常用
- additive
- 自主性提示称为查询(query)。感官输入被称为值(value)
- 计算得到当前query和其他key的不同attention score
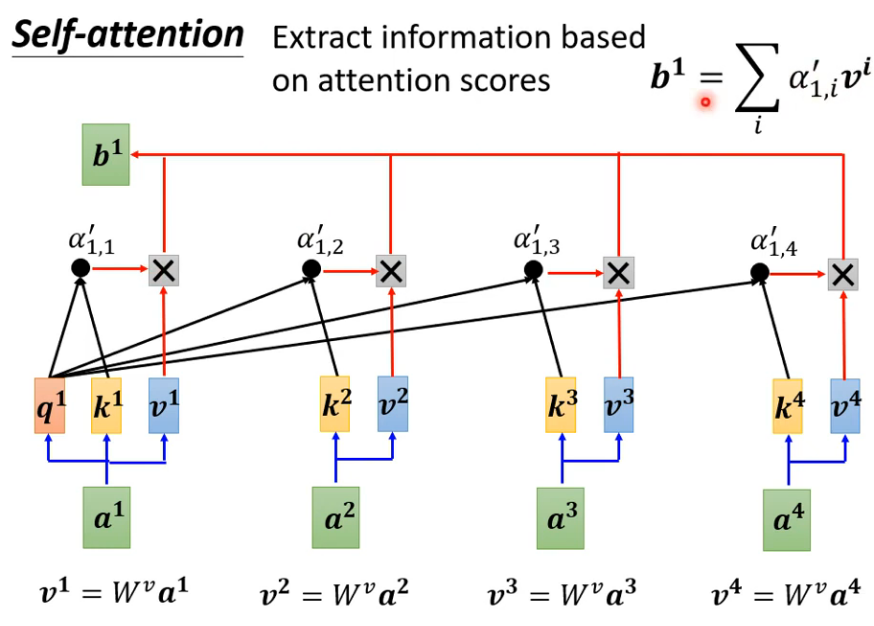
- 根据分数抽取重要资讯,attention score和矩阵v相乘得到当前向量b,谁分量大谁关联强
- 在原向量列表中确定当前向量相关的向量距离(关联程度)
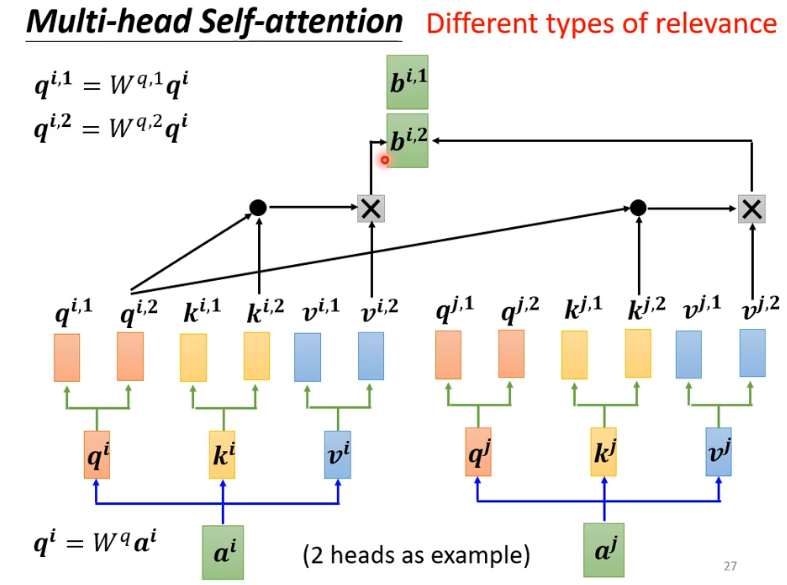
- position encoding 的ei直接加在ai上面,和位置有关,一般是手工设计好
- 自注意力和卷积:卷积是简化版的自注意力,cnn受一定限制,自注意力泛化效果好(数据量很大时)
- 自注意力和循环神经网络:平行和不平行运算,RNN中每个向量的关系和句子间距离也有关系越远影响越小,自注意力句子间和相对位置的差关系不大
Lecture 5:Sequence to sequence
大多NLP任务可以看作是阅读理解的问答模型QA,转换为seq2seq(问题+内容→回答)
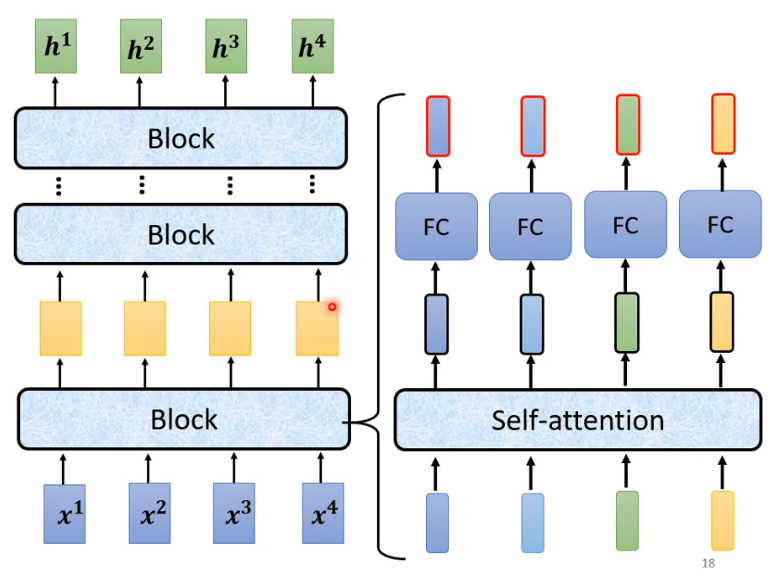
seq2seq化简就是input - encoder - decoder - output
transformer

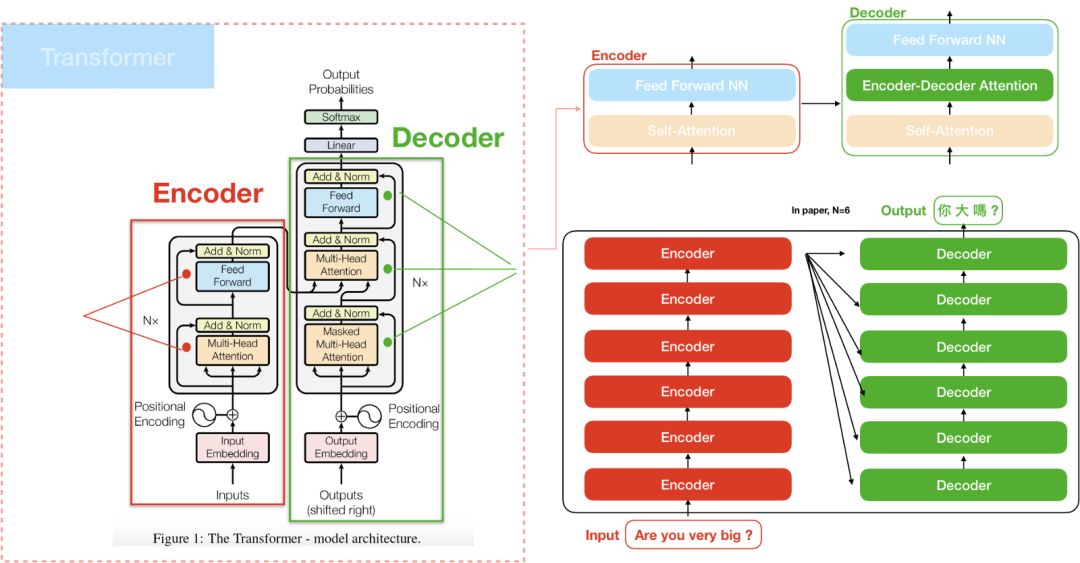
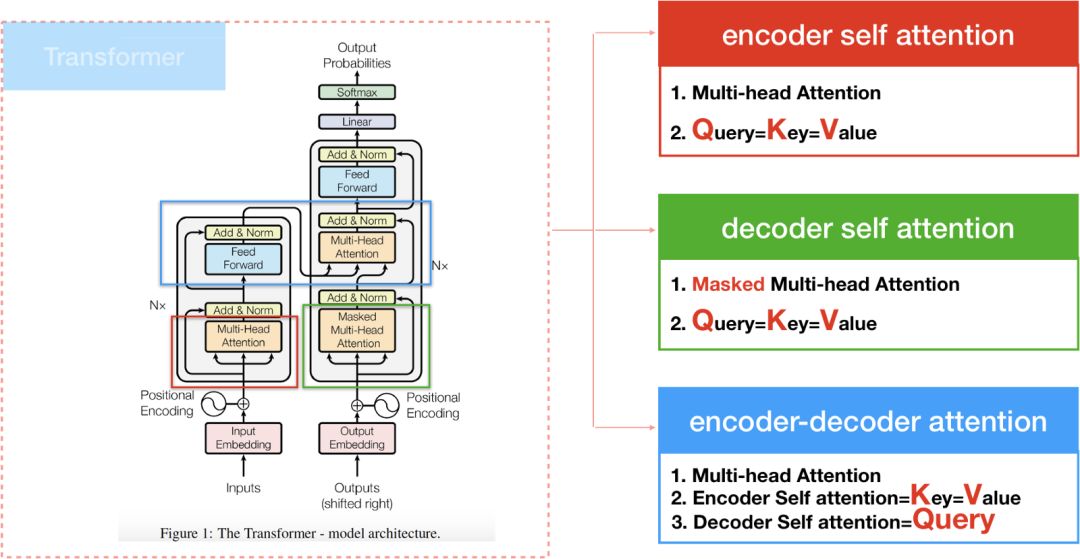
encoder内部部分
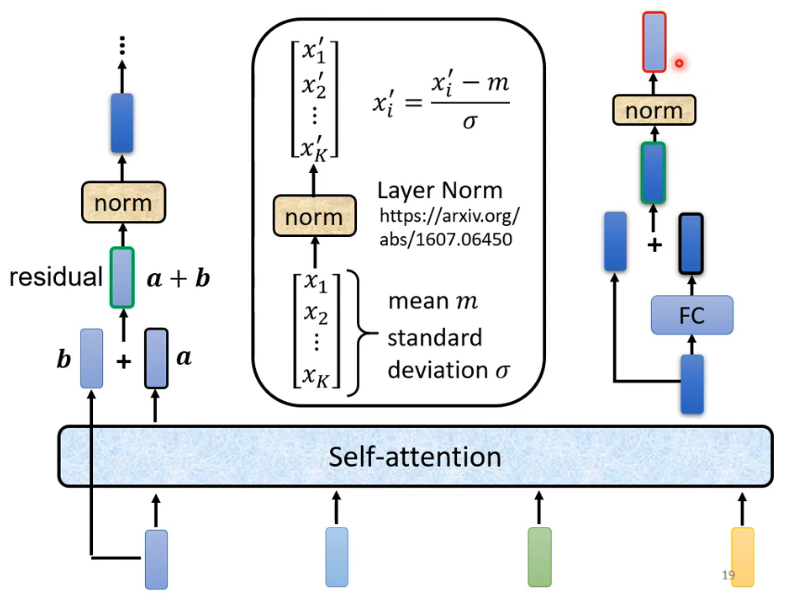
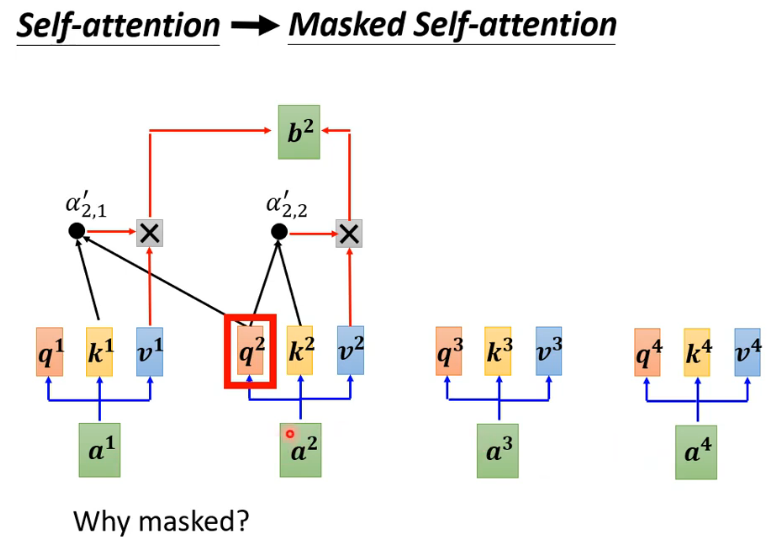
decoder内部部分 (有个mask)
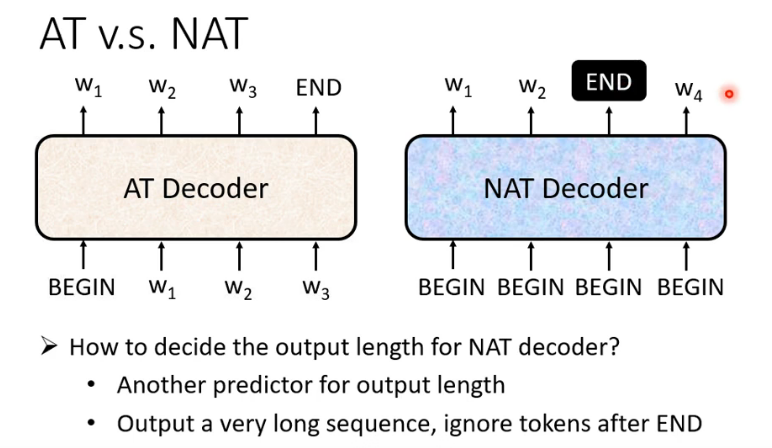
autoregressive
no autoregressive
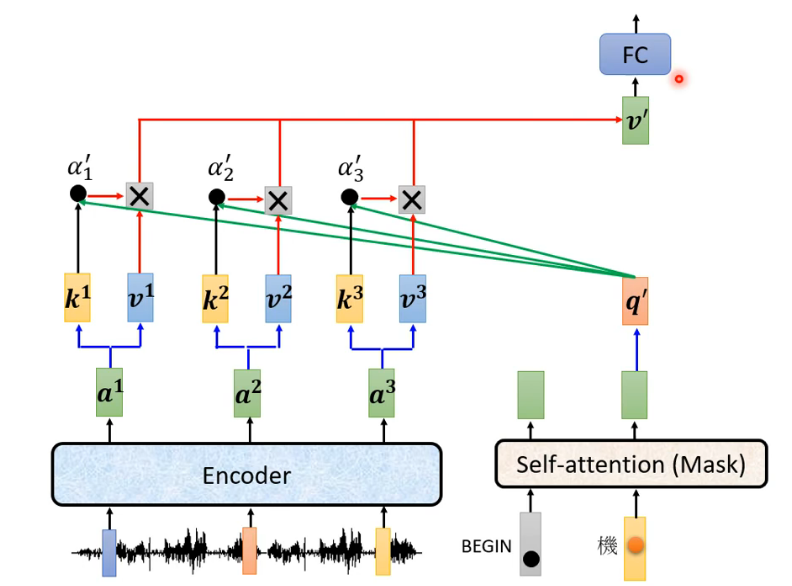
encoder-decoder的cross attention
对于每一个字 评估用最小交叉熵 对一句话用bleu和n-gram等方法
- tips
- copy特定的词汇
- guided attention 输入和输出单调对齐(语音由左向右方向)
- beam search:beam search有一个超参数beam size(束宽),设为k 。第一个时间步长,选取当前条件概率最大的 k 个词,当做候选输出序列的第一个词。之后的每个时间步长,基于上个步长的输出序列,挑选出所有组合中条件概率最大的k 个,作为该时间步长下的候选输出序列。始终保持 k 个候选。最后从k 个候选中挑出最优的。
- scheduleed sampling :把正确答案做为decoder的一部分input,为了防止mismatch(exposure bias 一步错步步错)就任意改动输入的几个字(但是伤害到transfomer的平行化)
Lecture 6: Generation
GAN的基本思想就是两个神经网络分别是generator和discriminator,其中生成器每次生成图像然后鉴别器会去判定判别生成器生成的图像 ,两者不断地生成判别相互对抗相互提升,到最后生成器生成的图像质量不断提升,判别器判别的能力也不断提升,这就是生成对抗式网络的基本思想,互相制约互相提高。
步骤
准备一个真实图片的数据集
随机初始化Generator和Discriminator,此时Generator生成图片是瞎生成,Discriminator也是瞎分辨
训练Discriminator:
3.1 让Generator生成一组图片,然后让Discriminator来分辨真假,同时也会告诉Discriminator真实的图片长什么样子
3.2. 根据第 3.1 步的损失来更新Discriminator
训练Generator:
4.1. 继续让Generator生成一组图片,然后让Discriminator来分别真假。注意,本次只会让Discriminator看生成的图片
4.2. 根据第 4.1 步得到的损失来更新Generator
重复迭代3,4步,直到满意为止
如果给定两个噪音向量之间连续的内差,Generator会告诉你这两个图片之间的过渡过程
GAN中生成器的目标是将输入的正态分布数据经过生成网络变成类似真实标签分布的数据,而为了让分布尽可能相似就必须最小化两个数据分布之间的距离
既然生成器的目标是最小化生成数据和真实数据之间的距离那么鉴别器就是最大化两者的距离,针对如何计算生成数据和真实数据之间的距离,引入了JS散度的概念来计算,事实上也可以看成是交叉熵乘一个负号
- 之前在计算网络输出和真实数据时往往都是一一对应的标签并且直接计算两者的L1或L2距离即可方便判断两个的差距,而在GAN中生成数据和真实数据往往不是一一对应,这就是JS divergence的巧妙之处,不需要知道生成数据和真实数据的具体形式,只需要通过鉴别器输出值和JS即可,当然不仅仅只有JS函数可以用还可以用其他很多的函数
- 使用JS divergence的很大缺点就是在于如果生成数据和真实数据采样不够多,两者之间没有任何重叠部分没有交集,那么JS计算出来的距离将恒等于log2,这将会直接导致generator无法提高 ,两者如果没有重叠即假设让divergence处于最大时即判别器最理想的时候,那么这时候计算出来的就是log2
- 推土机距离也称作Wasserstein distance,它最直观的好处就是当生成数据和真实数据无任何交集的时候它不会像JS一样处于恒等值的情况,这就使得generator可以一直往好的方向去发展而不是直接停止
公式

其中对于判别器,WGAN作出了限制即必须满足1-lipschitz的条件,该条件的目的是为了让生成数据和真实数据之间不会相差太大使得推算出来的推土机距离不会过大否则无任何意义,而WGAN中让判别器满足1-lipschitz的条件的方法其实相对较为简单
- WGAN中使用的就是推土机距离代替了JS距离,如图所示即为WGAN中新的距离公式:

条件GAN:额外输入一段向量规定生成的图像需要包含什么特征,这就是条件GAN,如其中额外输入的向量就是一段文字即将一段文字转换成vector输入generator和discriminator中 。
问题
quality
Diversity - Mode Collapse (找到了一个能骗过D的局部区域)
Diversity - Mode Dropping (类型没找完)
对于一张图片,类型要准确,对于一堆照片,要有多样性
三种标签 查看 xy是否匹配
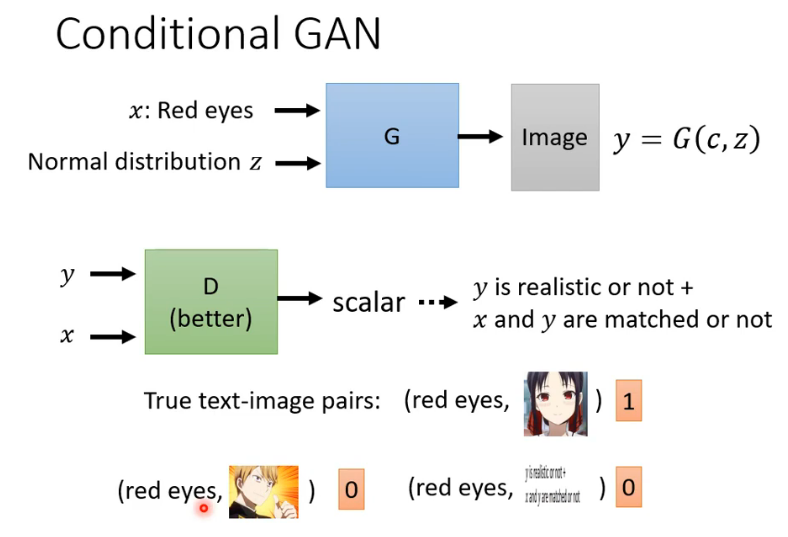
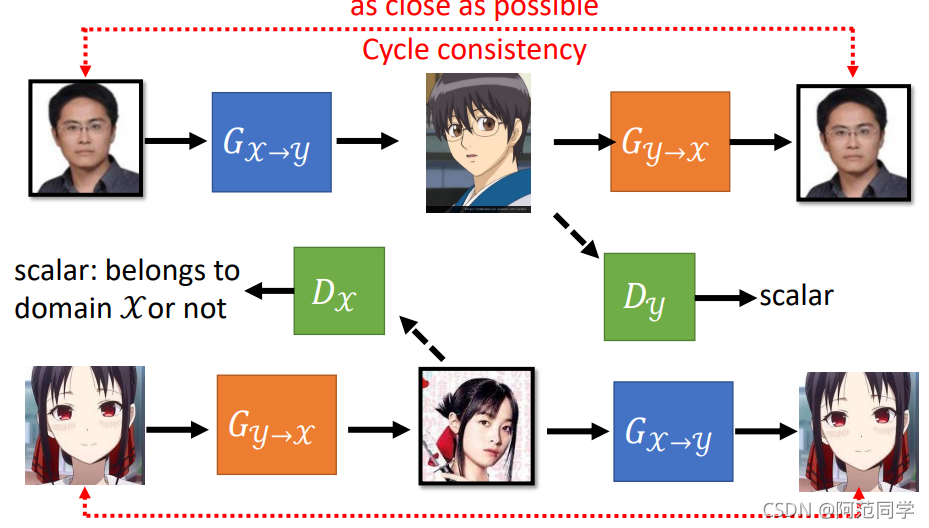
Learning from Unpaired Data: CycleGAN是典型风格转化生成的GAN,其主题思想是训练四个网络并形成一个Cycle输入一幅图像生成另一个风格图像再让生成图像生成回原来的图像风格,这样的一个形式就是CycleGAN的主要思想,事实上它在训练四个网络包括两个生成器和两个判别器
Recent Advance of Self-supervised learning for NLP
bert
监督学习和自监督学习self-supervised learning(在没有标注的情况下自行将数据进行分类/聚类,类似无监督学习)
bert在训练时执行,只学会做填空题(产生bert的过程叫做pre-train)
- mask input:加mask或者random,得到最小交叉熵
- Next Sentence Prediction(【cls】最初二分类预测两个句子相接与否 和【sep】)
但是可以做很多下游任务,只需要进行fine-tune
分类(情感分析):【cls】的输出进行训练
词性标注:每一个词向量的输出进行训练
两个句子输出一个类别(Natural Language Inferencee,NLI):【cls】…【sep】….,只取【cls】训练
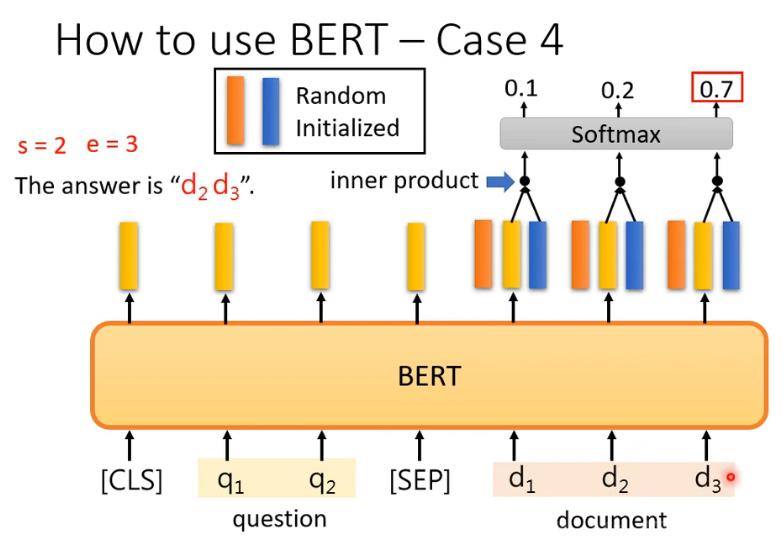
抽取式(QA Extraction-based Question Answering)输入文章D问题Q两个向量,输出切片索引值A
mask方法、bart方法:对ecoding的句子进行部分毁坏
- Transfer Text-to-Text Transformer (T5)
- Colossal Clean Crawled Corpus (C4)
bert填空类似word embbedding中的cbow
gpt
进行Predict Next Token(可以用于文章生成)
Few-shot/1-shot/0-shot Learning (不是梯度下降)“In-context” Learning