讯飞2024AI开发者大赛|基于超声数据的多病种疾病预测挑战赛上分记录
记录
8.21调整学习率跑baseline,线下f1macro和acc非常高甚至99,但是线上反而降了,考虑可能过拟合了,从训练数据上入手先分析数据

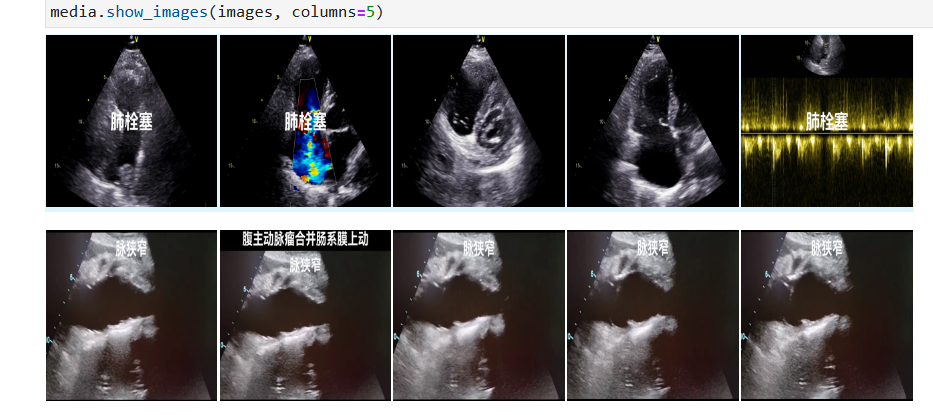
可以看标签名称和图像有关联,应该是来自于同一个视频,做了帧采样
还有个数据名称是
一看就是想打括号忘记加shift了
还有一堆重复的图,基本上没有什么变化,感觉是复制粘贴的,比如这个DCM的,就没动静,我觉得应该清洗掉,肯定是训练的时候这个太关注这个地方了
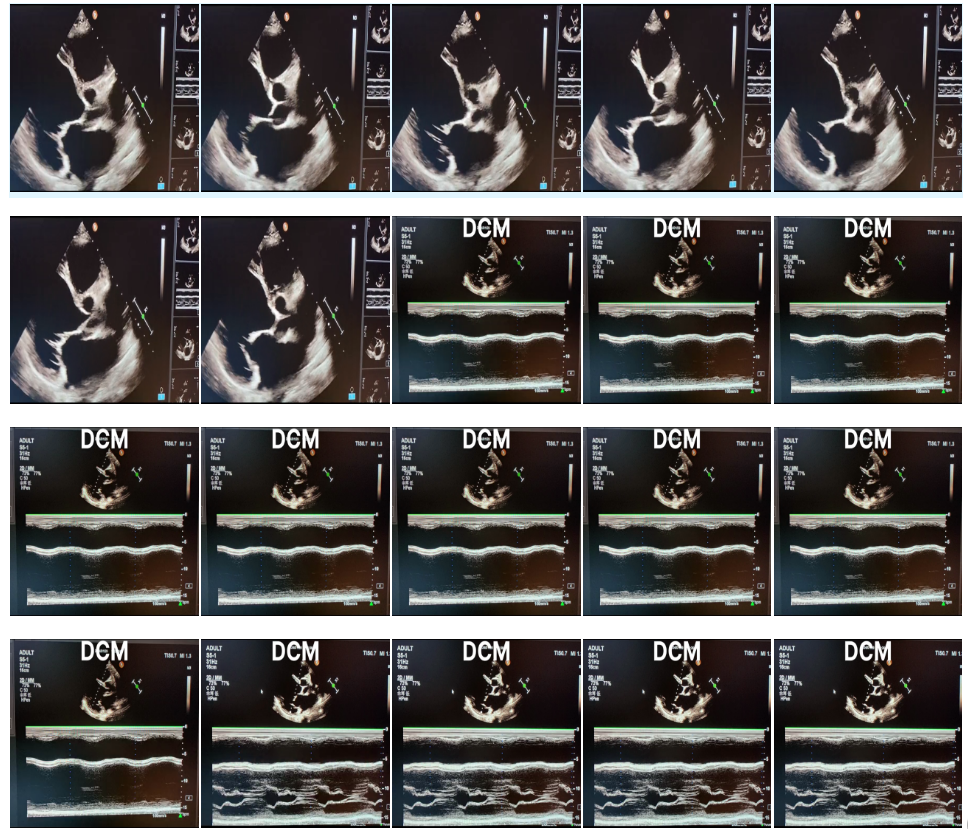
测试集也是也有一样的图
可以先做个聚类,把一样的图聚类在一起然后给一样的标签(要么都对了要么都寄了)
训练集有非医学影像 删除 ./data/train/Cyst/04/*.npy
没有内容的也要删除 ./data/train/Vascular/01/*.npy”
# 观察到数据往往是来自同一个视频# 首先进行数据清洗,手动根据训练集的标题,归到分别的文件夹中
# train_raw# ----类别1# --------01文件夹# ---------npy# --------02文件夹# ---------npy# ----类别2# --------01文件夹# ---------npy# --------02文件夹# ---------npy
# 手动删去train中非影像、文字装饰太多的图片(共7张)# 包括:# ./data/train/Cyst/04/05 (4)到10 (4).npy (非影像演示图)# ./data/train/Vascular/01/05.npy (文字装饰太多)
# 这个代码用来查看一个类中的所有图像,便于手动删除
# Anomalies 01-11 220 -> 220# Cyst 01-11 180 -> 174# Inflammation 01-11 180 -> 180# Tumor 01-13 250 -> 250# Vascular 01-11 159 -> 158
import numpy as npimport mediapy as mediaimport glob, os
for i in range(1,12): image_paths = sorted(glob.glob(f"./data/train/Anomalies/{i:02}/*.npy")) images = [] print(i) for image_path in image_paths: images.append(np.load(os.path.join(image_path))) media.show_images(images, columns=10)
# 针对训练集每一个类进行内部聚类,获取类内的聚类点特征# 减轻类内的数据不平衡、一些图片基本一致的影响
train_class_and_folder_num = { "Anomalies": 11, "Cyst": 11, "Inflammation": 11, "Tumor": 13, "Vascular": 11}
# 抽取图像特征# 获取resnet50特征
import torchimport torch.nn as nnimport torchvision.models as modelsimport torchvision.transforms as transformsfrom PIL import Image
class DemoNet(nn.Module): def __init__(self): super(DemoNet, self).__init__()
model = models.resnet50(pretrained=True) model.fc = torch.nn.Identity() self.model = model
def forward(self, img): out = self.model(img) return out
extract = DemoNet().cuda().eval()
transform = transforms.Compose([ transforms.Resize((256, 256)), transforms.ToTensor(),])
# 抽取图像特征# 遍历每个类
with torch.no_grad(): for idx, class_name in enumerate(train_class_and_folder_num): features = [] folder_num = train_class_and_folder_num[class_name] for i in range(1, folder_num+1): image_paths = sorted(glob.glob(f"./data/train/{class_name}/{i:02}/*.npy")) for image_path in image_paths: image = np.load(os.path.join(image_path)) image = Image.fromarray(image) image = transform(image).unsqueeze(0).cuda() feature = extract(image) features.append(feature) features = torch.cat(features, dim=0) torch.save(f"./data/train_class_{idx}.pt", features)
Comments