Publications
Note: # = Equal Contribution, * = Corresponding Author.
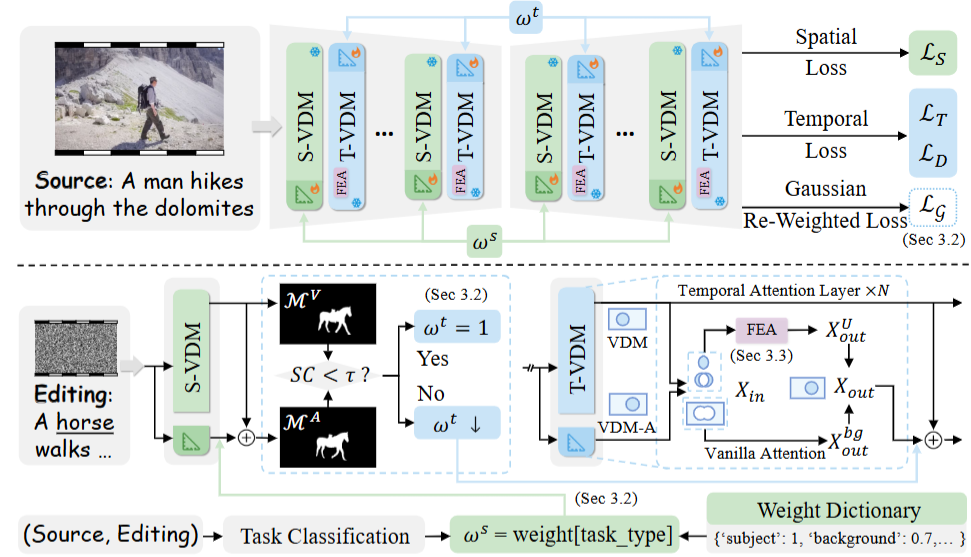
DRA-MTransfer: Physically Realistic Video Motion Transfer with Dual-Grained Re-Adaptation
TL;DR:DRA-MTransfer leverages dual-grained re-adaptation to unlock motion priors in video diffusion models, enhancing physical realism in motion transfer while maintaining fidelity and coherence.
Garments2Look: A Multi-Reference Dataset for High-Fidelity Outfit-Level Virtual Try-On with Clothing and Accessories
TL;DR:Garments2Look, the first outfit-level VTON dataset with 80K pairs, 40 categories, rich annotations, tests SOTA models and reveals their limitations in layering/styling.

Emotion-Director: Bridging Affective Shortcut in Emotion-Oriented Image Generation
TL;DR:Emotion-Director enhances text-to-image emotion control via a collaborative diffusion model, prompt rewriting agent, synthetic emotion data, and improved DPO fine-tuning.

ExtDM: Distribution Extrapolation Diffusion Model for Video Prediction
TL;DR:We present ExtDM, a new diffusion model that extrapolates video content from current frames by accurately modeling distribution shifts towards future frames.
