书生大模型实战营-L0-Python基础知识
本节任务要点
- Python实现wordcount
- Vscode连接InternStudio debug笔记
实践流程
实现wordcount
请实现一个wordcount函数,统计英文字符串中每个单词出现的次数。返回一个字典,key为单词,value为对应单词出现的次数。
Input:
"""Hello world!This is an example.Word count is fun.Is it fun to count words?Yes, it is fun!"""Output:
{'hello': 1, 'world': 1, 'this': 1, 'is': 4, 'an': 1, 'example': 1, 'word': 1, 'count': 2,'fun': 3, 'it': 2, 'to': 1, 'words': 1, 'yes': 1}TIPS:记得先去掉标点符号,然后把每个单词转换成小写。不需要考虑特别多的标点符号,只需要考虑实例输入中存在的就可以。
text = """Got this panda plush toy for my daughter's birthday,who loves it and takes it everywhere. It's soft andsuper cute, and its face has a friendly look. It'sa bit small for what I paid though. I think theremight be other options that are bigger for thesame price. It arrived a day earlier than expected,so I got to play with it myself before I gave itto her."""
def wordcount(text): pass直接交给kimi
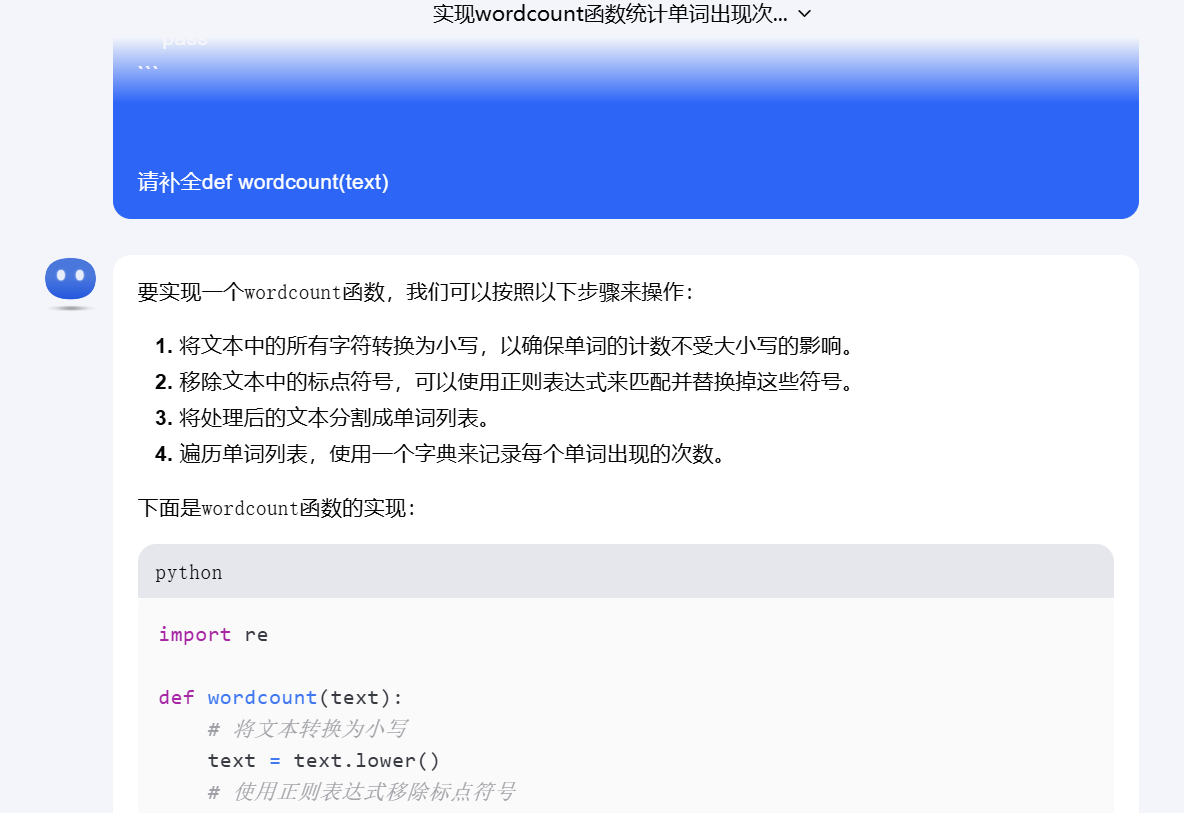
实际代码
text = """Hello world!This is an example.Word count is fun.Is it fun to count words?Yes, it is fun!"""
text1 = """Got this panda plush toy for my daughter's birthday,who loves it and takes it everywhere. It's soft andsuper cute, and its face has a friendly look. It'sa bit small for what I paid though. I think theremight be other options that are bigger for thesame price. It arrived a day earlier than expected,so I got to play with it myself before I gave itto her."""
import re
def wordcount(text): # 将文本转换为小写 text = text.lower() # 使用正则表达式移除标点符号 text = re.sub(r'[^\w\s]', '', text) # 分割文本为单词列表 words = text.split() # 创建一个字典来存储单词计数 word_count = {} # 遍历单词列表,计数 for word in words: if word in word_count: word_count[word] += 1 else: word_count[word] = 1 return word_count
print(wordcount(text))print(wordcount(text1))测试结果

连接InternStudio debug笔记
请使用本地vscode连接远程开发机,将上面你写的wordcount函数在开发机上进行debug,体验debug的全流程,并完成一份debug笔记(需要截图)。
在32行打点,表示第一次达到这个点的时候,应该是有一个单词已经出现过一次,才会进入这一行,查看text文本,这里进入的word是is,is正好出现第二次
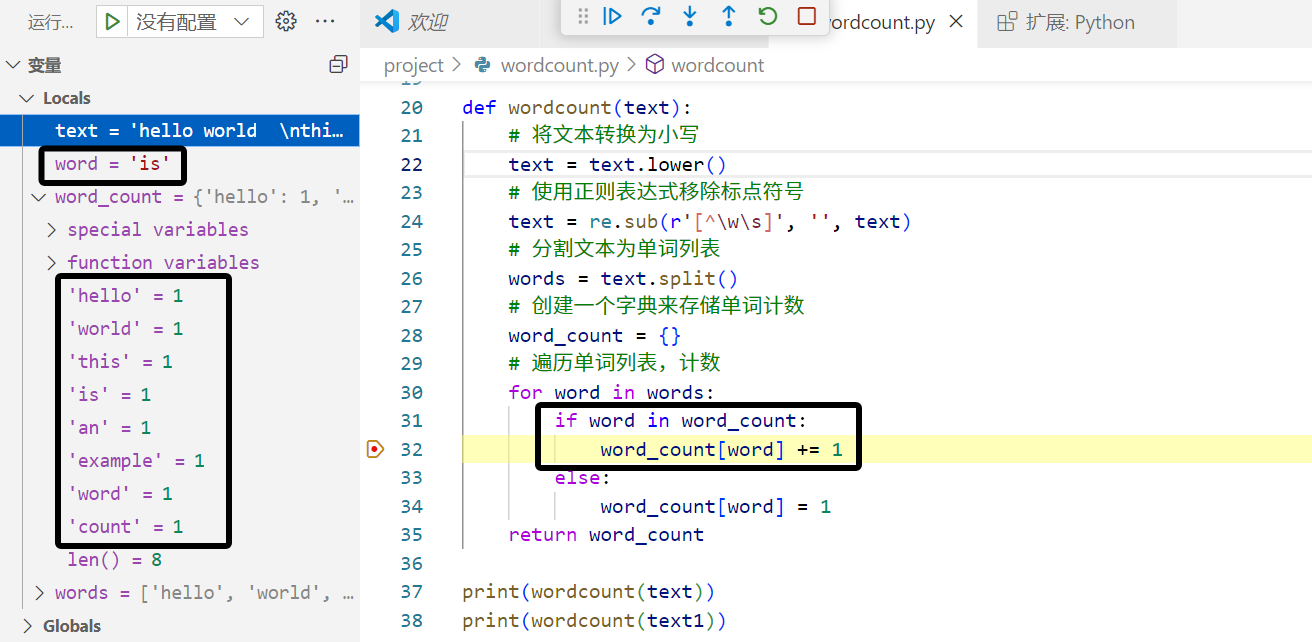
选择单步运行,发现word_count里面的is对应的数值已经是2了,增加了1
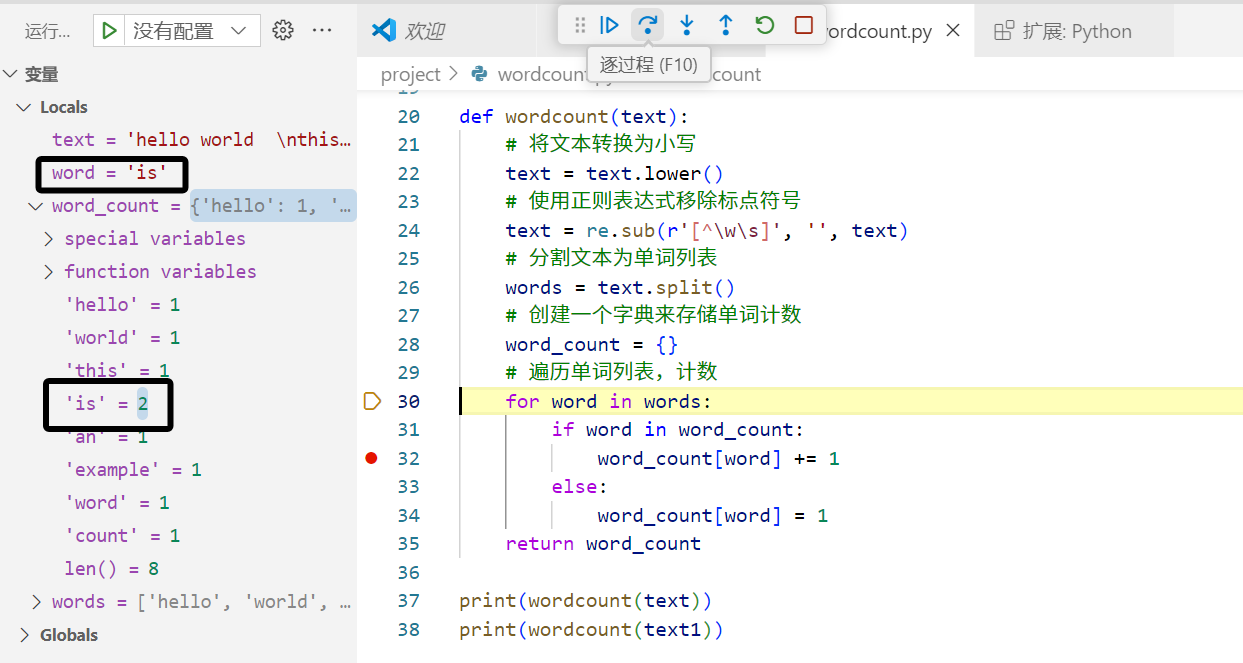
取消32行断点,设置35行断点,直接运行到该断点,左侧统计出了该text文本段所有词汇的出现次数。
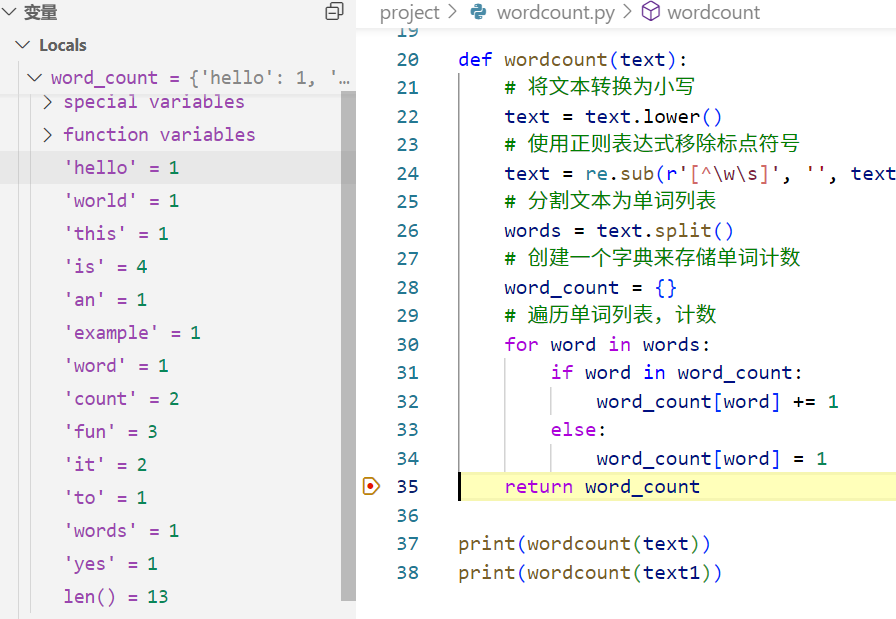
总结
温故知新,debug很好用,不要再总是一次次print了。ai编程也是个好东西,提高生产力。
Comments