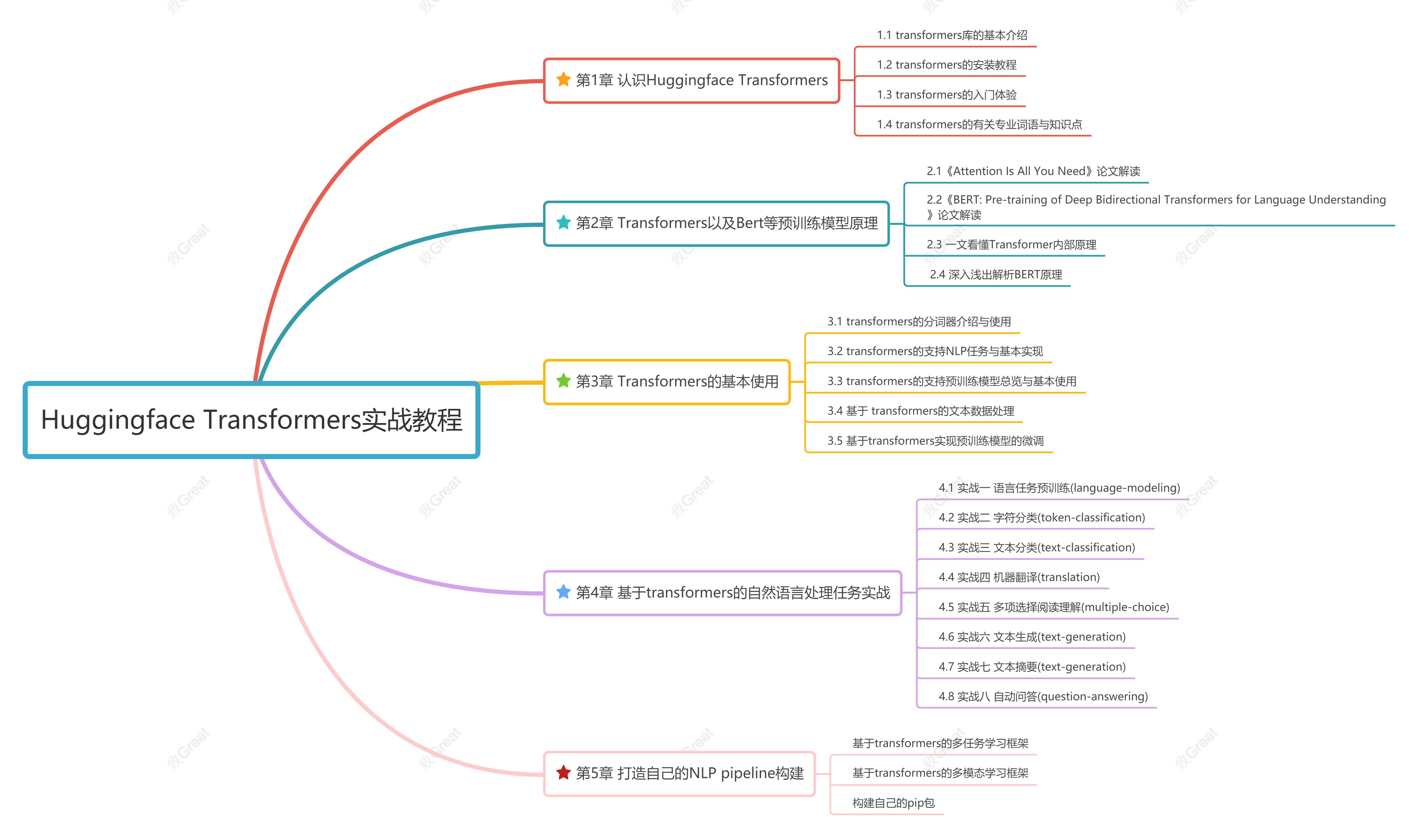
和鲸社区2022咸鱼打挺夏令营-【NLP最佳实践】Huggingface Transformers实战教程-笔记、作业答案与部分解析
简介
intro
!pip install -i https://pypi.tuna.tsinghua.edu.cn/simple transformers==4.3.1
from transformers import AutoTokenizer, AutoModelForMaskedLMtokenizer = AutoTokenizer.from_pretrained("bert-base-chinese")model = AutoModelForMaskedLM.from_pretrained("bert-base-chinese")
import torchfrom transformers import BertTokenizerfrom IPython.display import clear_output
PRETRAINED_MODEL_NAME = "bert-base-chinese"
# 取得此預訓練模型所使用的 tokenizertokenizer = BertTokenizer.from_pretrained(PRETRAINED_MODEL_NAME)
clear_output()
vocab = tokenizer.vocabprint("字典大小:", len(vocab)) # 字典大小: 21128除了一般的wordpieces 以外,BERT 里头有5 个特殊tokens 各司其职:
[CLS]:在做分类任务时其最后一层的repr. 会被视为整个输入序列的repr.
[SEP]:有两个句子的文本会被串接成一个输入序列,并在两句之间插入这个token 以做区隔
[UNK]:没出现在BERT 字典里头的字会被这个token 取代
[PAD]:zero padding 遮罩,将长度不一的输入序列补齐方便做batch 运算
[MASK]:未知遮罩,仅在预训练阶段会用到
如上例所示,[CLS]一般会被放在输入序列的最前面,而zero padding在之前的Transformer文章里已经有非常详细的介绍。[MASK]token一般在fine-tuning或是feature extraction时不会用到,这边只是为了展示预训练阶段的遮蔽字任务才使用的。
text = "[CLS] 等到潮水 [MASK] 了,就知道谁沒穿裤子。"tokens = tokenizer.tokenize(text)ids = tokenizer.convert_tokens_to_ids(tokens)
print(text)print(tokens[:10], '...')print(ids[:10], '...')
"""[CLS] 等到潮水 [MASK] 了,就知道谁沒穿裤子。['[CLS]', '等', '到', '潮', '水', '[MASK]', '了', ',', '就', '知'] ...[101, 5023, 1168, 4060, 3717, 103, 749, 8024, 2218, 4761] ..."""
from transformers import BertForMaskedLM# 除了 tokens 以外我們還需要辨別句子的 segment idstokens_tensor = torch.tensor([ids]) # (1, seq_len)segments_tensors = torch.zeros_like(tokens_tensor) # (1, seq_len)maskedLM_model = BertForMaskedLM.from_pretrained(PRETRAINED_MODEL_NAME)
# 使用 masked LM 估計 [MASK] 位置所代表的實際 tokenmaskedLM_model.eval()with torch.no_grad(): outputs = maskedLM_model(tokens_tensor, segments_tensors) predictions = outputs[0] # (1, seq_len, num_hidden_units)del maskedLM_model
# 將 [MASK] 位置的機率分佈取 top k 最有可能的 tokens 出來masked_index = 5k = 3probs, indices = torch.topk(torch.softmax(predictions[0, masked_index], -1), k)predicted_tokens = tokenizer.convert_ids_to_tokens(indices.tolist())
# 顯示 top k 可能的字。一般我們就是取 top 1 当做预测值print("輸入 tokens :", tokens[:10], '...')print('-' * 50)for i, (t, p) in enumerate(zip(predicted_tokens, probs), 1): tokens[masked_index] = t print("Top {} ({:2}%):{}".format(i, int(p.item() * 100), tokens[:10]), '...')
"""輸入 tokens : ['[CLS]', '等', '到', '潮', '水', '[MASK]', '了', ',', '就', '知'] ...--------------------------------------------------Top 1 (65%):['[CLS]', '等', '到', '潮', '水', '来', '了', ',', '就', '知'] ...Top 2 ( 4%):['[CLS]', '等', '到', '潮', '水', '过', '了', ',', '就', '知'] ...Top 3 ( 4%):['[CLS]', '等', '到', '潮', '水', '干', '了', ',', '就', '知'] ..."""文本数据处理
文本数据的基本特征提取
#主要要学会使用apply+lambda
# 词汇数量train['word_count']=train['tweet'].apply(lambda x:len(str(x).split(" ")))train[['tweet','word_count']].head()
# 字符数量train['char_count']=train['tweet'].str.len()train[['tweet','char_count']].head()
# 平均字长def avg_word(sentence): words=sentence.split() return (sum(len(word) for word in words)/len(words))
train['avg_word']=train['tweet'].apply(lambda x:avg_word(x))train[['tweet','avg_word']].head()
# 停用词数量"""为节省存储空间和提高搜索效率,搜索引擎在索引页面或处理搜索请求时会自动忽略某些字或词,这些字或词即被称为Stop Words(停用词)。"""!pip install nltkimport nltknltk.download('stopwords')from nltk.corpus import stopwordsstop=stopwords.words('english')
train['stopwords']=train['tweet'].apply(lambda sen:len([x for x in sen.split() if x in stop]))train[['tweet','stopwords']].head()
# 特殊字符数量train['hashtags']=train['tweet'].apply(lambda sen:len([x for x in sen.split() if x.startswith("#")]))train[['tweet','hashtags']].head()
# 数字数量train['numerics']=train['tweet'].apply(lambda sen:len([x for x in sen.split() if x.isdigit()]))train[['tweet','numerics']].head()
# 大写字母数量train['upper']=train['tweet'].apply(lambda sen:len([x for x in sen.split() if x.isupper()]))train[['tweet','upper']].head()文本数据的基本预处理
# 小写转换"""这避免了拥有相同的多个副本。例如,当我们计算字词汇数量时,“Analytics”和“analytics”将被视为不同的单词。"""train['tweet']=train['tweet'].apply(lambda sen:" ".join(x.lower() for x in sen.split()))train['tweet'].head()
# 去除标点符号"""标点符号在文本数据中不添加任何额外的信息"""train['tweet'] = train['tweet'].str.replace('[^\w\s]','')train['tweet'].head()
# 去除停用词from nltk.corpus import stopwordsstop=stopwords.words('english')train['tweet']=train['tweet'].apply(lambda sen:" ".join(x for x in sen.split() if x not in stop))train['tweet'].head()
# 去除频现词freq=pd.Series(' '.join(train['tweet']).split()).value_counts()[:10]freq"""user 17473love 2647ð 2511day 2199â 1797happy 1663amp 1582im 1139u 1136time 1110"""freq=list(freq.index)train['tweet']=train['tweet'].apply(lambda sen:' '.join(x for x in sen.split() if x not in freq))train['tweet'].head()
# 去除稀疏词freq = pd.Series(' '.join(train['tweet']).split()).value_counts()[-10:]freqfreq = list(freq.index)train['tweet'] = train['tweet'].apply(lambda x: " ".join(x for x in x.split() if x not in freq))train['tweet'].head()
# 拼写校正!pip install textblobfrom textblob import TextBlobtrain['tweet'][:5].apply(lambda x: str(TextBlob(x).correct()))
# 分词(tokenization)import nltknltk.download('punkt')TextBlob(train['tweet'][1]).words
# 词干提取(stemming)"""是指通过基于规则的方法去除单词的后缀,比如“ing”,“ly”,“s”等等。"""from nltk.stem import PorterStemmerst=PorterStemmer()train['tweet'][:5].apply(lambda x:" ".join([st.stem(word) for word in x.split()]))
# 词形还原(lemmatization)from textblob import Wordtrain['tweet']=train['tweet'].apply(lambda x:" ".join([Word(word).lemmatize() for word in x.split()]))train['tweet'].head()高级文本处理
# N-grams语言模型"""N-grams称为N元语言模型,是多个词语的组合,是一种统计语言模型,用来根据前(n-1)个item来预测第n个item。常见模型有一元语言模型(unigrams)、二元语言模型(bigrams )、三元语言模型(trigrams)。Unigrams包含的信息通常情况下比bigrams和trigrams少,需要根据具体应用选择语言模型,因为如果n-grams太短,这时不能捕获重要信息。另一方面,如果n-grams太长,那么捕获的信息基本上是一样的,没有差异性"""TextBlob(train['tweet'][0]).ngrams(2)
# 词频tf1 = (train['tweet'][1:2]).apply(lambda x: pd.value_counts(x.split(" "))).sum(axis = 0).reset_index()tf1.columns = ['words','tf']tf1
# 逆文档频率"""反转文档频率(Inverse Document Frequency),简称为IDF,其原理可以简单理解为如果一个单词在所有文档都会出现,那么可能这个单词对我们没有那么重要。一个单词的IDF就是所有行数与出现该单词的行的个数的比例,最后对数。"""import numpy as npfor i,word in enumerate(tf1['words']): tf1.loc[i, 'idf'] =np.log(train.shape[0]/(len(train[train['tweet'].str.contains(word)])))tf1
# TF-IDF"""TF-IDF=TF*IDF"""from sklearn.feature_extraction.text import TfidfVectorizertfidf = TfidfVectorizer(max_features=1000, lowercase=True, analyzer='word', stop_words= 'english',ngram_range=(1,1))train_vect = tfidf.fit_transform(train['tweet'])train_vect
# 词袋"""BOW,就是将文本/Query看作是一系列词的集合。由于词很多,所以咱们就用袋子把它们装起来,简称词袋。"""from sklearn.feature_extraction.text import CountVectorizerbow = CountVectorizer(max_features=1000, lowercase=True, ngram_range=(1,1),analyzer = "word")train_bow = bow.fit_transform(train['tweet'])train_bow
# 情感分析from textblob import TextBlobtestimonial = TextBlob("Textblob is amazingly simple to use. What great fun!")print(testimonial.sentiment)"""Sentiment(polarity=0.39166666666666666, subjectivity=0.4357142857142857)"""
# 词嵌入from gensim.scripts.glove2word2vec import glove2word2vecglove_input_file = 'glove.6B.100d.txt'word2vec_output_file = 'glove.6B.100d.txt.word2vec'glove2word2vec(glove_input_file, word2vec_output_file)01-认识transformers
Bert
BERT的网络架构使用的是《Attention is all you need》中提出的多层Transformer结构。其最大的特点是抛弃了传统的RNN和CNN,通过Attention机制将任意位置的两个单词的距离转换成1,有效的解决了NLP中棘手的长期依赖问题。
BERT整体框架包含pre-train和fine-tune两个阶段。pre-train阶段模型是在无标注的标签数据上进行训练,进行参数初始化,然后所有的参数会用下游的有标注的数据进行训练。
BERT是用了Transformer的encoder侧的网络,encoder中的Self-attention机制在编码一个token的时候同时利用了其上下文的token。
Embedding
Embedding由三种Embedding求和而成:
Token Embeddings是词向量,第一个单词是CLS标志,可以用于之后的分类任务
Segment Embeddings用来区别两种句子,因为预训练不光做LM还要做以两个句子为输入的分类任务
Position Embeddings和之前文章中的Transformer不一样,不是三角函数而是学习出来的
其中[CLS]表示该特征用于分类模型,对非分类模型,该符号可以省去。[SEP]表示分句符号,用于断开输入语料中的两个句子。
BERT在第一句前会加一个[CLS]标志,最后一层该位对应向量可以作为整句话的语义表示,从而用于下游的分类任务等。因为与文本中已有的其它词相比,这个无明显语义信息的符号会更“公平”地融合文本中各个词的语义信息,从而更好的表示整句话的语义。 具体来说,self-attention是用文本中的其它词来增强目标词的语义表示,但是目标词本身的语义还是会占主要部分的,因此,经过BERT的12层(BERT-base为例),每次词的embedding融合了所有词的信息,可以去更好的表示自己的语义。而[CLS]位本身没有语义,经过12层,句子级别的向量,相比其他正常词,可以更好的表征句子语义。
主要代码
# ---------- 安装 ----------
git lfs installgit clone https://huggingface.co/hfl/chinese-roberta-wwm-ext# if you want to clone without large files – just their pointers# prepend your git clone with the following env var:GIT_LFS_SKIP_SMUDGE=1
"""from transformers import AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained("ckiplab/albert-tiny-chinese")
model = AutoModelForMaskedLM.from_pretrained("ckiplab/albert-tiny-chinese")"""
# ---------- 导入 ----------
from transformers import AutoConfig,AutoModel,AutoTokenizer,AdamW,get_linear_schedule_with_warmup,loggingimport torchimport torch.nn as nnimport torch.nn.functional as Ffrom torch.utils.data import TensorDataset,SequentialSampler,RandomSampler,DataLoaderMODEL_NAME="bert-base-chinese"# MODEL_NAME="roberta-large"
# ---------- 查看配置 ----------config = AutoConfig.from_pretrained(MODEL_NAME)config
# ---------- tokenizer ----------
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)tokenizer"""PreTrainedTokenizerFast(name_or_path='bert-base-chinese', vocab_size=21128, model_max_len=512, is_fast=True, padding_side='right', truncation_side='right', special_tokens={'unk_token': '[UNK]', 'sep_token': '[SEP]', 'pad_token': '[PAD]', 'cls_token': '[CLS]', 'mask_token': '[MASK]'})"""
tokenizer.all_special_ids"""[100, 102, 0, 101, 103]"""
tokenizer.all_special_tokens"""['[UNK]', '[SEP]', '[PAD]', '[CLS]', '[MASK]']"""
# 词汇表大小tokenizer.vocab_size # 21128
# ---------- 将文本转为词汇表id 1 (encode) ----------"""encode( self, text, text_pair, add_special_tokens, padding, truncation, max_length, stride, return_tensors, **kwargs ) -> List[int]Converts a string to a sequence of ids (integer), using the tokenizer and vocabulary."""
text="我在北京工作"token_ids=tokenizer.encode(text)token_ids# [101, 2769, 1762, 1266, 776, 2339, 868, 102]tokenizer.convert_ids_to_tokens(token_ids)# ['[CLS]', '我', '在', '北', '京', '工', '作', '[SEP]']
# 加入参数token_ids=tokenizer.encode(text,padding=True,max_length=30,add_special_tokens=True)token_ids# [101, 2769, 1762, 1266, 776, 2339, 868, 102] 这个还是不变token_ids=tokenizer.encode(text,padding="max_length",max_length=30,add_special_tokens=True)token_ids# [101, 2769, 1762, 1266, 776, 2339, 868, 102,0,0,0,.....] padding到30token_ids=tokenizer.encode(text,padding="max_length",max_length=30,add_special_tokens=True,return_tensors='pt')token_ids# 返回pytorch tensor格式的列表
# ---------- 将文本转为词汇表id 2 (encode_plus) ----------""" 确实是plus版本 主要是返回相关的参数多了def encode_plus( self, text, text_pair, add_special_tokens, padding, truncation, max_length, stride, return_tensors, return_tensors, return_token_type_ids, return_attention_mask, return_overflowing_tokens, return_special_tokens_mask, return_offsets_mapping, return_length, verbose, **kwargs ) -> BatchEncoding:"""
token_ids=tokenizer.encode_plus( text,padding="max_length", max_length=30, add_special_tokens=True, return_tensors='pt', return_token_type_ids=True, return_attention_mask=True)token_ids
"""返回1.pytorch的tensor格式id2.token_type_ids3.attention_mask
{ 'input_ids': tensor([ [ 101, 2769, 1762, 1266, 776, 2339, 868, 102, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0] ]), 'token_type_ids': tensor([ [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0] ]), 'attention_mask': tensor([ [1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0] ])}"""
# ---------- Model ----------model=AutoModel.from_pretrained(MODEL_NAME)model
"""查看模型结构
BertModel( (embeddings): BertEmbeddings( (word_embeddings): Embedding(21128, 768, padding_idx=0) (position_embeddings): Embedding(512, 768) (token_type_embeddings): Embedding(2, 768) (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True) (dropout): Dropout(p=0.1, inplace=False) ) (encoder): BertEncoder( (layer): ModuleList( (0)-(11): BertLayer( # 12个一样的BertLayer构成encoder (attention): BertAttention( (self): BertSelfAttention( (query): Linear(in_features=768, out_features=768, bias=True) (key): Linear(in_features=768, out_features=768, bias=True) (value): Linear(in_features=768, out_features=768, bias=True) (dropout): Dropout(p=0.1, inplace=False) ) (output): BertSelfOutput( (dense): Linear(in_features=768, out_features=768, bias=True) (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True) (dropout): Dropout(p=0.1, inplace=False) ) ) (intermediate): BertIntermediate( (dense): Linear(in_features=768, out_features=3072, bias=True) (intermediate_act_fn): GELUActivation() ) (output): BertOutput( (dense): Linear(in_features=3072, out_features=768, bias=True) (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True) (dropout): Dropout(p=0.1, inplace=False) ) ) ) ) (pooler): BertPooler( (dense): Linear(in_features=768, out_features=768, bias=True) (activation): Tanh() ))"""
# ---------- 输出 ----------
outputs=model(token_ids['input_ids'],token_ids['attention_mask'])
outputs.keys()"""odict_keys(['last_hidden_state', 'pooler_output'])"""
last_hidden_state=outputs[0].shape # last_hidden_state, torch.Size([1, 30, 768])outputs[1].shape # 句子pooler_output, torch.Size([1, 30, 768])outputs[0][:,0].shape # 第一个字符CLS的embedding表示 torch.Size([1, 768])
# ---------- 对Bert输出进行变换 ----------config.update({ 'output_hidden_states':True })model=AutoModel.from_pretrained(MODEL_NAME,config=config)outputs=model(token_ids['input_ids'],token_ids['token_type_ids'])outputs.keys()"""odict_keys(['last_hidden_state', 'pooler_output', 'hidden_states'])"""作业与答案
- Q1 HuggingFace的中文名称叫什么?
A. 抱抱脸 [√]B. 娃娃脸C. 笑笑脸- Q2 HuggingFace transformers的github地址为?
A. https://github.com/UKPLab/sentence-transformersB. https://github.com/huggingface/transformers [√]C. https://github.com/CompVis/taming-transformers- Q3 HuggingFace transformers的模型仓库地址为?
A. https://huggingface.co/docsB. https://huggingface.co/datasetsC. https://huggingface.co/models [√]- Q4 阅读以下代码,回答问题:
token_ids=tokenizer.encode_plus( text,padding="max_length", max_length=30, add_special_tokens=True, return_tensors='pt', return_token_type_ids=True, return_attention_mask=True)问题:上述代码输出token_ids的主键有几个?具体值为:
A. 3;attention_mask,input_ids,token_type_ids [√]B. 2;attention_mask,token_type_idsC. 1;input_idsD. 1;token_type_ids- Q5 阅读以下代码,回答问题:
config.update({ 'output_hidden_states':True })model=AutoModel.from_pretrained(MODEL_NAME,config=config)outputs=model(token_ids['input_ids'],token_ids['token_type_ids'])问题:上述代码输出outputs的主键有几个?具体值为:
A. 2last_hidden_state;pooler_outputB. 2;hidden_states;pooler_outputC. 3;hidden_states;last_hidden_state;pooler_output [√]D. 1;pooler_output02-文本分类实战:基于Bert的企业隐患排查分类模型
作业与答案
- Q1 Pytorch中查看GPU是否可用,下列代码片段适用的是?
A. torch.cuda.is_available() [√]B. torch.cuda.is_initialized()C. torch.cuda.current_device()- Q2 对于代码段
print(train.shape[0]-train.count())作用,
其中train为pandas的DataFrame,对象下列描述正确的是,?
A. 统计train中数据列数B. 统计train中每列空值的个数 [√]C. 统计train中数据行数- Q3 BertTokenizer的词汇表汇,下列哪些符号是特殊符号?
1. [SEP]2. [UNK]3. [PAD]4. [CLS]5. [MASK]
A. 123B. 234C. 145D. 12345 [√]- Q4 BertTokenizer的词表大小为多少?
A. 21128 [√]B. 21126C. 21120D. 21132- Q5 阅读下面代码,其中bert_model 为’bert-base-chinese’,encoding为ids个数为32,说法正确的是?
last_hidden_state, pooled_output = bert_model( input_ids=encoding['input_ids'], attention_mask=encoding['attention_mask'], return_dict = False)
A. last_hidden_state.shape的大小为[1, 32, 768] [√]B. pooled_output.shape的大小为[1, 512] # torch.Size([1, 768])C. bert_model.config.hidden_size的大小为512 # 76803-文本多标签分类实战:基于Bert对推特文本进行多标签分类
笔记
重要步骤
df['one_hot_labels'] = list(df[label_cols].values) # 直接将六个标签转为one hotlabels = list(df.one_hot_labels.values)comments = list(df.comment_text.values)
tokenizer = AutoTokenizer.from_pretrained()encodings = tokenizer.batch_encode_plus()
input_ids = encodings['input_ids'] # tokenized and encoded sentencestoken_type_ids = encodings['token_type_ids'] # token type idsattention_masks = encodings['attention_mask'] # attention masks
# 训练集和验证集划分
train_inputs, validation_inputs,train_labels, validation_labels,train_token_types, validation_token_types,train_masks, validation_masks = train_test_split( input_ids, labels, token_type_ids, attention_masks, random_state=2020, test_size=0.10, stratify = labels )
label_counts = df.one_hot_labels.astype(str).value_counts()one_freq = label_counts[label_counts==1].keys()one_freq_idxs = sorted(list(df[df.one_hot_labels.astype(str).isin(one_freq)].index), reverse=True)
# Gathering single instance inputs to force into the training set after stratified splitone_freq_input_ids = [input_ids.pop(i) for i in one_freq_idxs]one_freq_token_types = [token_type_ids.pop(i) for i in one_freq_idxs]one_freq_attention_masks = [attention_masks.pop(i) for i in one_freq_idxs]one_freq_labels = [labels.pop(i) for i in one_freq_idxs]
# Add one frequency data to train datatrain_inputs.extend(one_freq_input_ids)train_labels.extend(one_freq_labels)train_masks.extend(one_freq_attention_masks)train_token_types.extend(one_freq_token_types)
# 将原始id转为 torch 张量train_inputs = torch.tensor(train_inputs)train_labels = torch.tensor(train_labels)train_masks = torch.tensor(train_masks)train_token_types = torch.tensor(train_token_types)
validation_inputs = torch.tensor(validation_inputs)validation_labels = torch.tensor(validation_labels)validation_masks = torch.tensor(validation_masks)validation_token_types = torch.tensor(validation_token_types)
batch_size = 32
# 训练集train_data = TensorDataset(train_inputs, train_masks, train_labels, train_token_types)train_sampler = RandomSampler(train_data) #train_dataloader = DataLoader(train_data, sampler=train_sampler, batch_size=batch_size)
validation_data = TensorDataset(validation_inputs, validation_masks, validation_labels, validation_token_types)validation_sampler = SequentialSampler(validation_data) # 按顺序遍历validation_dataloader = DataLoader(validation_data, sampler=validation_sampler, batch_size=batch_size)
torch.save(validation_dataloader,'validation_data_loader')torch.save(train_dataloader,'train_data_loader')
from transformers import AutoModelForSequenceClassification# 加载预训练模型model = AutoModelForSequenceClassification.from_pretrained("bert-base-uncased", num_labels=num_labels)# num_labels:6 默认情况2分类
paras=[para for para in model.named_parameters()]
from transformers import AdamW# 对不同参数设置weight_decay_rateparam_optimizer = list(model.named_parameters())no_decay = ['bias', 'gamma', 'beta']optimizer_grouped_parameters = [ {'params': [p for n, p in param_optimizer if not any(nd in n for nd in no_decay)], 'weight_decay_rate': 0.01}, {'params': [p for n, p in param_optimizer if any(nd in n for nd in no_decay)], 'weight_decay_rate': 0.0}]
optimizer = AdamW(optimizer_grouped_parameters,lr=2e-5,correct_bias=True)# 1e-5,2e-5,5e-5# optimizer = AdamW(model.parameters(),lr=2e-5) # 默认优化器
# Store our loss and accuracy for plottingtrain_loss_set = []
# Number of training epochs (authors recommend between 2 and 4)epochs = 3 # 训练轮数,15万训练集 任务比较简单的,最多设置5
# trange is a tqdm wrapper around the normal python rangefor _ in trange(epochs, desc="Epoch"): # Training # Set our model to training mode (as opposed to evaluation mode) model.train() # 设置训练模式
# Tracking variables tr_loss = 0 #running loss nb_tr_examples, nb_tr_steps = 0, 0
# Train the data for one epoch for step, batch in enumerate(train_dataloader):# 遍历批数据 # Add batch to GPU batch = tuple(t.to(device) for t in batch) b_input_ids, b_input_mask, b_labels, b_token_types = batch optimizer.zero_grad()
# loss = outputs[0] # logits = outputs[1]
outputs = model(b_input_ids, token_type_ids=None, attention_mask=b_input_mask) logits = outputs[0] loss_func = BCEWithLogitsLoss() # 计算损失 loss = loss_func( logits.view(-1,num_labels), b_labels.type_as(logits).view(-1,num_labels) ) train_loss_set.append(loss.item())# 记录loss
# Backward pass loss.backward() # loss反向求导 # Update parameters and take a step using the computed gradient optimizer.step() tr_loss += loss.item() nb_tr_examples += b_input_ids.size(0) nb_tr_steps += 1
print("Train loss: {}".format(tr_loss/nb_tr_steps))
# Validation
# Put model in evaluation mode to evaluate loss on the validation set model.eval()
# Variables to gather full output logit_preds,true_labels,pred_labels,tokenized_texts = [],[],[],[]
# Predict for i, batch in enumerate(validation_dataloader): batch = tuple(t.to(device) for t in batch) # Unpack the inputs from our dataloader b_input_ids, b_input_mask, b_labels, b_token_types = batch with torch.no_grad(): # Forward pass outs = model( b_input_ids, token_type_ids=None, attention_mask=b_input_mask )
b_logit_pred = outs[0] pred_label = torch.sigmoid(b_logit_pred)
b_logit_pred = b_logit_pred.detach().cpu().numpy() pred_label = pred_label.to('cpu').numpy() b_labels = b_labels.to('cpu').numpy()
tokenized_texts.append(b_input_ids) logit_preds.append(b_logit_pred) true_labels.append(b_labels) pred_labels.append(pred_label)
# Flatten outputs pred_labels = [item for sublist in pred_labels for item in sublist] true_labels = [item for sublist in true_labels for item in sublist]
# 计算准确率 threshold = 0.50 pred_bools = [pl>threshold for pl in pred_labels] true_bools = [tl==1 for tl in true_labels] val_f1_accuracy = f1_score(true_bools,pred_bools,average='micro')*100 val_flat_accuracy = accuracy_score(true_bools, pred_bools)*100
print('F1 Validation Accuracy: ', val_f1_accuracy) print('Flat Validation Accuracy: ', val_flat_accuracy)
torch.save(model.state_dict(), 'bert_model_toxic')
...
# Test
test_encodings = tokenizer.batch_encode_plus(test_comments)test_input_ids = test_encodings['input_ids']test_token_type_ids = test_encodings['token_type_ids']test_attention_masks = test_encodings['attention_mask']
# Make tensors out of datatest_inputs = torch.tensor(test_input_ids)test_labels = torch.tensor(test_labels)test_masks = torch.tensor(test_attention_masks)test_token_types = torch.tensor(test_token_type_ids)
# Create test dataloadertest_data = TensorDataset(test_inputs, test_masks, test_labels, test_token_types)test_sampler = SequentialSampler(test_data)test_dataloader = DataLoader(test_data, sampler=test_sampler, batch_size=batch_size)
# Save test dataloadertorch.save(test_dataloader,'test_data_loader')
# Put model in evaluation mode to evaluate loss on the validation setmodel.eval()
#track variableslogit_preds,true_labels,pred_labels,tokenized_texts = [],[],[],[]
# Predictfor i, batch in enumerate(test_dataloader): batch = tuple(t.to(device) for t in batch) # Unpack the inputs from our dataloader b_input_ids, b_input_mask, b_labels, b_token_types = batch with torch.no_grad(): # Forward pass outs = model(b_input_ids, token_type_ids=None, attention_mask=b_input_mask) b_logit_pred = outs[0] pred_label = torch.sigmoid(b_logit_pred)
b_logit_pred = b_logit_pred.detach().cpu().numpy() pred_label = pred_label.to('cpu').numpy() b_labels = b_labels.to('cpu').numpy()
tokenized_texts.append(b_input_ids) logit_preds.append(b_logit_pred) true_labels.append(b_labels) pred_labels.append(pred_label)
# Flatten outputstokenized_texts = [item for sublist in tokenized_texts for item in sublist]pred_labels = [item for sublist in pred_labels for item in sublist]true_labels = [item for sublist in true_labels for item in sublist]# Converting flattened binary values to boolean valuestrue_bools = [tl==1 for tl in true_labels]pred_bools = [pl>0.50 for pl in pred_labels] #boolean output after thresholding
idx2label = dict(zip(range(6),label_cols))
# Getting indices of where boolean one hot vector true_bools is True so we can use idx2label to gather label namestrue_label_idxs, pred_label_idxs=[],[]for vals in true_bools: true_label_idxs.append(np.where(vals)[0].flatten().tolist())for vals in pred_bools: pred_label_idxs.append(np.where(vals)[0].flatten().tolist())
# Gathering vectors of label names using idx2labeltrue_label_texts, pred_label_texts = [], []for vals in true_label_idxs: if vals: true_label_texts.append([idx2label[val] for val in vals]) else: true_label_texts.append(vals)
for vals in pred_label_idxs: if vals: pred_label_texts.append([idx2label[val] for val in vals]) else: pred_label_texts.append(vals)
# Decoding input ids to comment textcomment_texts = [tokenizer.decode(text,skip_special_tokens=True,clean_up_tokenization_spaces=False) for text in tokenized_texts]
# Converting lists to dfcomparisons_df = pd.DataFrame({'comment_text': comment_texts, 'true_labels': true_label_texts, 'pred_labels':pred_label_texts})comparisons_df.to_csv('comparisons.csv')comparisons_df.head()
macro_thresholds = np.array(range(1,10))/10macro_thresholds
f1_results, flat_acc_results = [], []for th in macro_thresholds: pred_bools = [pl>th for pl in pred_labels] test_f1_accuracy = f1_score(true_bools,pred_bools,average='micro') test_flat_accuracy = accuracy_score(true_bools, pred_bools) f1_results.append(test_f1_accuracy) flat_acc_results.append(test_flat_accuracy)
best_macro_th = macro_thresholds[np.argmax(f1_results)] #best macro threshold value
micro_thresholds = (np.array(range(10))/100)+best_macro_th #calculating micro threshold values
f1_results, flat_acc_results = [], []for th in micro_thresholds: pred_bools = [pl>th for pl in pred_labels] test_f1_accuracy = f1_score(true_bools,pred_bools,average='micro') test_flat_accuracy = accuracy_score(true_bools, pred_bools) f1_results.append(test_f1_accuracy) flat_acc_results.append(test_flat_accuracy)
best_f1_idx = np.argmax(f1_results) #best threshold value
# Printing and saving classification reportprint('Best Threshold: ', micro_thresholds[best_f1_idx])print('Test F1 Accuracy: ', f1_results[best_f1_idx])print('Test Flat Accuracy: ', flat_acc_results[best_f1_idx], '\n')
best_pred_bools = [pl>micro_thresholds[best_f1_idx] for pl in pred_labels]clf_report_optimized = classification_report(true_bools,best_pred_bools, target_names=label_cols)pickle.dump(clf_report_optimized, open('classification_report_optimized.txt','wb'))print(clf_report_optimized)作业与答案
- Q1 二分类、多分类与多标签的拼写分别对应为?
- Multiclass classification- Multilabel classification- Binary classification
A. 123B. 312 [√]C. 321- Q2 对于多标签分类,选用下列哪个损失函数比较适合,
A. BCEWithLogitsLoss [√]B. CrossEntropyLossC. L1loss- Q3 对于多标签分类任务,标签是否需要转为one-hot表示?
A. 需要 [√]B. 不需要- Q4 对于多标签分类模型,对于“某个标签0.5一定是最优阈值”,这句话是否正确?
A. 错误 [√]B. 正确- Q5 对于多标签分类任务,下列可以作为其评估指标?
A. precisionB. recallC. f1-scoreD. ABC都可以 [√]04-句子相似性识别实战
作业与答案
- Q1 句子相似性识别 类似于 Bert两种预训练哪个任务?
A. MLMB. NSP [√]- Q2 阅读下面代码,选择正确的描述,
encoded_pair = self.tokenizer(sent1, sent2, padding='max_length', # Pad to max_length truncation=True, # Truncate to max_length max_length=self.maxlen, return_tensors='pt') # Return torch.Tensor objects
A. encoded_pair['token_type_ids']中返回值中全是0B. encoded_pair['token_type_ids']中返回值中针对sent1的toeken值为0,sent2的token值为1 [√]C. encoded_pair['token_type_ids']中返回值中全是1- Q3 关于梯度累加gradient accumulation作用,下列描述正确的是?
A. gradient accumulation可以增加GPU内存B. 通过gradient accumulation的手段,可以实现与采用大batch size相近的效果。 [√]- Q4 关于04-句子相似性识别实战:基于Bert对句子对进行相似性二分类.ipynb中的代码作用,下列描述是否正确 ?
if freeze_bert: for p in self.bert_layer.parameters(): p.requires_grad = False
A. 冻结Bert预训练模型参数更新 [√]B. 对Bert预训练模型参数进行梯度清零C. 删除Bert预训练模型参数- Q5 固定随机种子的作用?
def set_seed(seed): """ Set all seeds to make results reproducible """ torch.manual_seed(seed) torch.cuda.manual_seed_all(seed) torch.backends.cudnn.deterministic = True torch.backends.cudnn.benchmark = False np.random.seed(seed) random.seed(seed) os.environ['PYTHONHASHSEED'] = str(seed)
A. 保证结果的可复现性 [√]B. 保证模型参数的多样性C. 加快模型收敛05-命名实体识别实战
作业与答案
- Q1 Bert 编码器采用的模型结构为?
A. rnnB. cnnC. transformers [√]D. MLP- Q2 Bert的Embedding描述,不包括下列哪一个?
A.Token EmbeddingB.Segment EmbeddingC.Position EmbeddingD.Graph Embedding [√]- Q3 官方Bert-Base模型的hidden size为多少
A. 512B. 256C. 768 [√]D. 1024- Q4 Bert 采用哪种Normalization结构?
LayerNorm [√]BatchNorm- Q5 Bert的预训练任务包括哪些
A. Masked LMB. Next Sentence PredictionC. 两个都是 [√]06-多项选择任务实战:基于Bert在多项选择任务上微调模型
作业与答案
- Q1 以数据集SWAG 的MultipleChoice任务输入为例,下列描述正确的是?
A. 在输入上下文,问题选项句子对时,如果文本长度超过模型最大输入长度,应该截断 问题 文本B. 在输入上下文,问题选项句子对时,如果文本长度超过模型最大输入长度,应该截断 上下文 文本 [√]C. 在输入上下文,问题选项句子对时,如果文本长度超过模型最大输入长度,应该截断 选项 文本- Q2 在huggingface/transformers中,tokenizer的truncation截断策略不包括下列哪一个?
A.only_firstB.only_secondC.longest_firstD.full [√]- Q3 设置tokenizer滑窗步长大小的参数为哪一个?
A. max_lengthB. truncationC. return_overflowing_tokensD. stride [√]- Q4 基于transformers进行多项选择任务微调,应该基于哪个模型结构?
A. AutoModelForNextSentencePredictionB. AutoModelForSequenceClassificationC. AutoModelForTokenClassificationD. AutoModelForMultipleChoice [√]- Q5 关于MultiChoice任务评估指标选取,下列哪一个比较合适?
A. Accuracy [√]B. AucC. RMSE07-文本生成实战:基于预训练模型实现文本文本生成
作业与答案
- Q1 文本生成任务按照输入数据分类,有哪些类?
(1).文本到文本的生成;(2).数据到文本的生成;(3).图像到文本的生成。
A.(1)B.(2)(3)C.以上都是 [√]- Q2 下列哪个选项不适合作为文本生成的评估指标?
A.BLEUB.NISTC.AUC [√]D.ROUGE- Q3 GPT2与Bert的异同点,下列描述正确的是?
A. GPT2与BERT都使用了基于transformers的Encoder结构B. GPT2与BERT两者预训练任务相同C. Bert和GPT-2都采用的是transformer作为底层结构 [√]D. GPT2与BERT的Decoder部分完全一致- Q4 AutoModelForCausalLM加载的gpt2模型的可以支持解码方式的有哪些?
A. 贪心搜索B. 集束搜索C. 温度采样方法D. 以上都可以 [√]- Q5 关于解码方法,下列描述是否正确?
在文本生成任务中,没有一个确定的"最佳"解码方法。哪种方法最好,取决于你生成文本的任务性质以及当前语料。
A. 正确 [√]B. 错误08-文本摘要实战:基于Bert实现文本摘要任务
作业与答案
- Q1 下列可以用来做抽取式摘要的算法是?
A. TextRank [√]B. SVMC. Random Forest- Q2 基于深度学习进行文本摘要的主要模型结构为?
A.LSTMB.CNNC.Seq2Seq [√]D.GRU- Q3 下列哪个预训模型不是合适做文本摘要任务?
A. Bert [√]B. T5C. BARTD. PEGASUS- Q4 BLEU和ROUGE都可以作为文本摘要的评估指标
A. 正确 [√]B. 错误- Q5 关于tokenizer.as_target_tokenizer() 的作用,下列描述是否正确?
有些模型在解码器输入中需要特殊的标记,所以区分编码器和解码器输入的标记很重要。在with语句(称为上下文管理器)中,标记器知道它正在为解码器进行标记,并可以相应地处理序列。
A. 错误B. 正确 [√]09-文本翻译实战:基于Bert实现端到端的机器翻译
作业与答案
- Q1 基于transformers进行文本翻译任务微调,应该基于哪个模型结构?
A. AutoModelForNextSentencePredictionB. AutoModelForSequenceClassificationC. AutoModelForTokenClassificationD. AutoModelForSeq2SeqLM [√]- Q2 在tokenizer.as_target_tokenizer()作用下,改代码片段tokenizer.convert_ids_to_tokens(model_input[‘input_ids’])会添加哪个特殊符号?
A.<s>B.<mask>C.</s> [√]D.<sep>- Q3 SacreBLEU该工具包主要解决了文本翻译评价指标的什么问题?
A. 已有的计算方式需要用户自己提供tokenize过的结果,甚至还要提供tokenize过的参考译文,而不同人tokenize的方式不同,产生的结果就会不同 [√]B. 计算不准确C. 速度慢10-问答实战:基于预训练模型实现QA
作业与答案
- Q1 自动问答的类别,按照数据来源可以划分为?
1. 检索式问答2. 社区问答3. 知识库问答
A.1B.23C.123 [√]- Q2 自动问答的类别,按照问答范围可以划分为?
1. 开放域问答2. 垂直域问答
A.1B.2C.12 [√]- Q3 在本次抽取式任务中,模型预测是什么?
A. 答案在上下文的开始位置和结束位置的概率 [√]B. 答案的每个词发生的概率C. 选择某个句子的概率- Q4 tokenizer中return_offsets_mapping=True的时候返回的是什么?
A. token对应的idB. token在原始文本中的偏移位置 [√]C. token在原始文本中的句子id- Q5 基于transformers进行QA任务微调,应该基于哪个模型结构?
A. AutoModelForNextSentencePredictionB. AutoModelForSequenceClassificationC. AutoModelForQuestionAnswering [√]D. AutoModelForSeq2SeqLMlist
- 语言基础
- 栈
- 队列
- 链表
- 树
- 图
- 堆
- 散列表
- Matplotlib
- 特征选择
- 回归分析
- 描述统计
- 时间序列分析
- 概率论
- Numpy
- Pandas
- Pytorch
- scikit-learn
- 逻辑回归
- 贝叶斯分类器
- K临近
- K-means 聚类
- 线性回归
- 支持向量机
- 决策树
- 集成学习 boosting/ bagging/ stacking
- 梯度下降
- 误差反向传播
- 滑动平均
- 自适应步长
- 学习率衰减
- 权值初始化
- L2正则化
- 随机失活
- 数据扩充
- 早停
- 神经网络
- 激活函数
- 卷积神经网络 CNN
- 图像特征提取
- 文本预处理(分词)
- 文本分类
- BERT
- Transformer
- 散列表
Comments