糖尿病遗传风险检测挑战赛 - Coggle 30 Days of ML(22年7月)
任务1:报名比赛
-
步骤1:报名比赛http://challenge.xfyun.cn/topic/info?type=diabetes&ch=ds22-dw-zmt05

-
步骤2:下载比赛数据(点击比赛页面的赛题数据)

-
步骤3:解压比赛数据,并使用pandas进行读取
import pandas as pdtrain_df = pd.read_csv('./比赛训练集.csv', encoding='gbk')test_df = pd.read_csv('./比赛测试集.csv', encoding='gbk')print(train_df.shape,test_df.shape)
-
步骤4:查看训练集和测试集字段类型
train_df.dtypestest_df.dtypes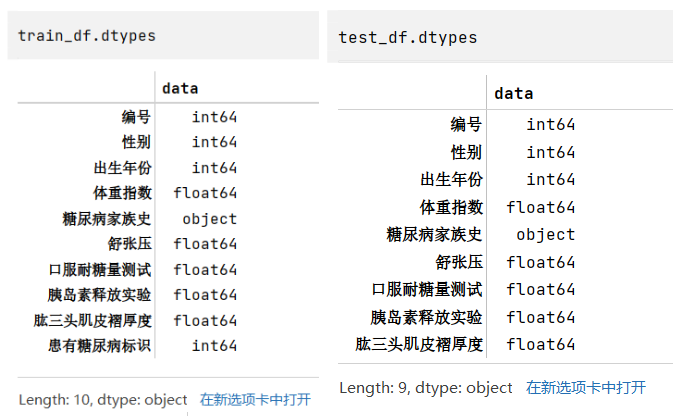
任务2:比赛数据分析
-
步骤1:统计字段的缺失值,计算缺失比例;
- 通过缺失值统计,训练集和测试集的缺失值分布是否一致?
- 通过缺失值统计,有没有缺失比例很高的列?
train_nan_df = pd.DataFrame(columns=['标签','训练集缺失个数','训练集缺失比例'])i = 0for tag in list(train_df.columns):num = train_df[tag].isnull().sum()num_rate = num/len(train_df)train_nan_df.loc[i] = [tag, num, num_rate]i += 1# train_nan_dftest_nan_df = pd.DataFrame(columns=['标签','测试集缺失个数','测试集缺失比例'])i = 0for tag in list(test_df.columns):num = test_df[tag].isnull().sum()num_rate = num/len(test_df)test_nan_df.loc[i] = [tag, num, num_rate]i += 1# test_nan_dftrain_nan_df.merge(test_nan_df,how='left')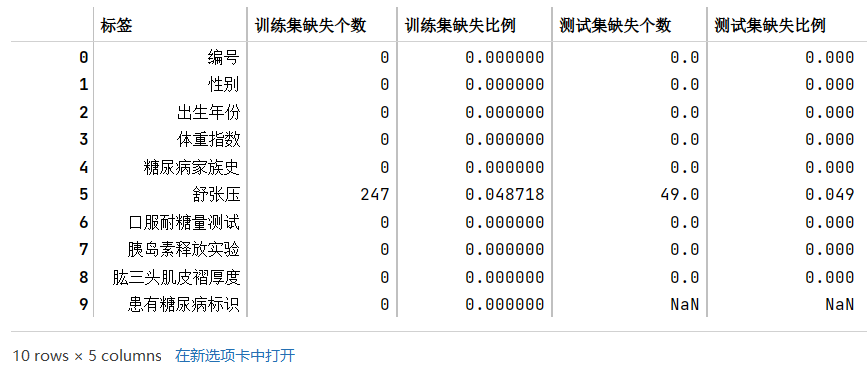
根据结果可知,训练集和测试集的缺失值分布一致,都是有且只有舒张压这一个标签含缺失值,且比例都在4.8-4.9%左右,缺失的比例其实也不算是特别高。
-
步骤2:分析字段的类型
- 有多少数值类型、类别类型?
- 你是判断字段类型的?
train_df.head() # tail() train_category_num_df = pd.DataFrame(columns=['标签','训练集该标签不同值个数'])i = 0for tag in list(train_df.columns):num = len(train_df[tag].value_counts())train_category_num_df.loc[i] = [tag, num]i += 1# train_category_num_dftest_category_num_df = pd.DataFrame(columns=['标签','测试集该标签不同值个数'])i = 0for tag in list(test_df.columns):num = len(test_df[tag].value_counts())test_category_num_df.loc[i] = [tag, num]i += 1# test_category_num_dftrain_category_num_df.merge(test_category_num_df,how='left')# 列包含NaN,因此dtype必须升级为浮点dtype以容纳
train_category_num_df = pd.DataFrame(columns=['标签','训练集该标签不同值个数'])i = 0for tag in list(train_df.columns):num = len(train_df[tag].value_counts())train_category_num_df.loc[i] = [tag, num]i += 1# train_category_num_dftest_category_num_df = pd.DataFrame(columns=['标签','测试集该标签不同值个数'])i = 0for tag in list(test_df.columns):num = len(test_df[tag].value_counts())test_category_num_df.loc[i] = [tag, num]i += 1# test_category_num_dftrain_category_num_df.merge(test_category_num_df,how='left')# 列包含NaN,因此dtype必须升级为浮点dtype以容纳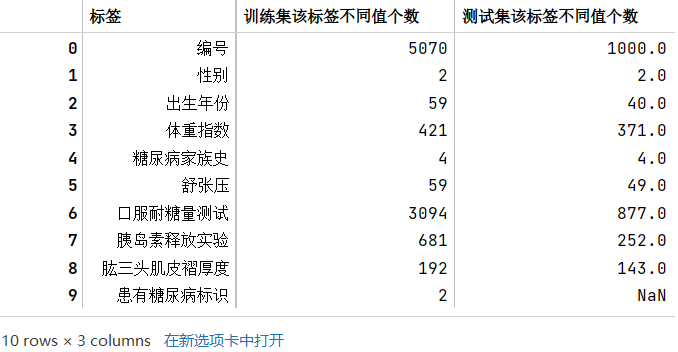
字段类型的判断主要通过根据常识(如性别)、观察原始数据(如糖尿病家族史)、以及各个标签的类型数量(如数量较多的可能就是连续性数据,是数值类型)来判断
- 数值类型:编号(和时序无关,后期没必要研究),出生年份,体重指数,舒张压,口服耐糖量测试,胰岛素释放实验,肱三头肌皮褶厚度
- 类别类型:性别(两类),糖尿病家族史(类型),患有糖尿病标识
- 当然,后期为了改善模型效果,也可以将一些连续性数据转换成类别,比如体重指数可以根据国家标准划分胖瘦类型,成为类别类型
- 其中,糖尿病家族史有四类,但是查看其类型,和“叔叔或者姑姑有一方患有糖尿病”应是同一表述,但是被分到两类,应该合并成一类为“叔叔或姑姑有一方患有糖尿病”
train_df.糖尿病家族史.value_counts()train_df.loc[train_df.糖尿病家族史 == '叔叔或者姑姑有一方患有糖尿病','糖尿病家族史'] = '叔叔或姑姑有一方患有糖尿病'train_df.糖尿病家族史.value_counts()train_df['糖尿病家族史'] = train_df['糖尿病家族史'].astype('int64')test_df['糖尿病家族史'] = test_df['糖尿病家族史'].astype('int64')train_df.dtypes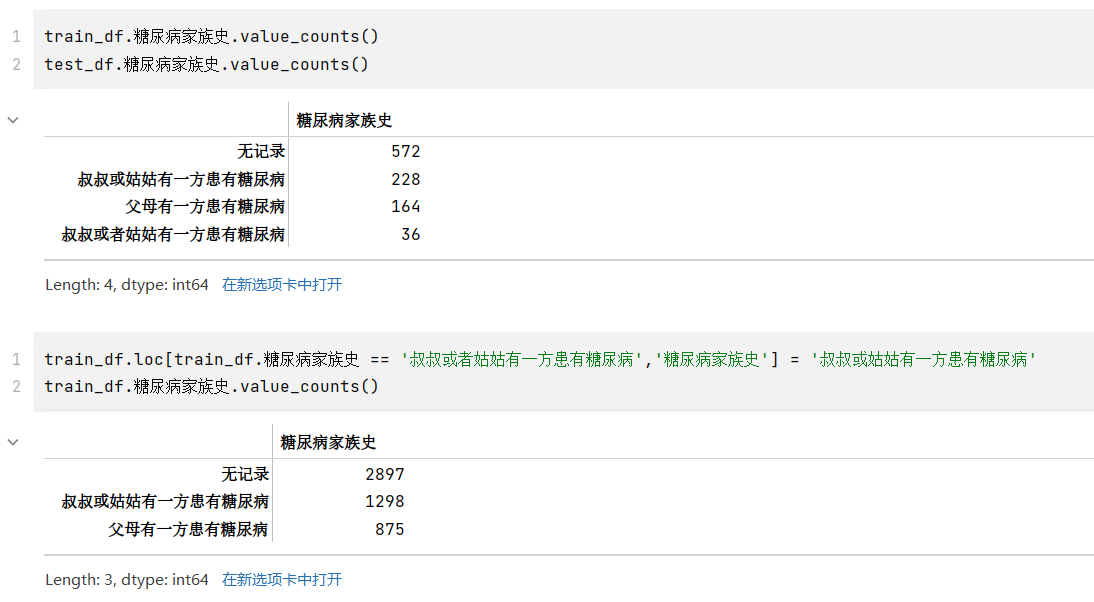
步骤3:计算字段相关性
- 通过
.corr()计算字段之间的相关性 - 有哪些字段与标签的相关性最高?
- 尝试使用其他可视化方法将字段 与 标签的分布差异进行可视化
tag_list = train_df.columns.tolist()tag_list.pop(tag_list.index("编号"))corr = train_df[tag_list].corr()corr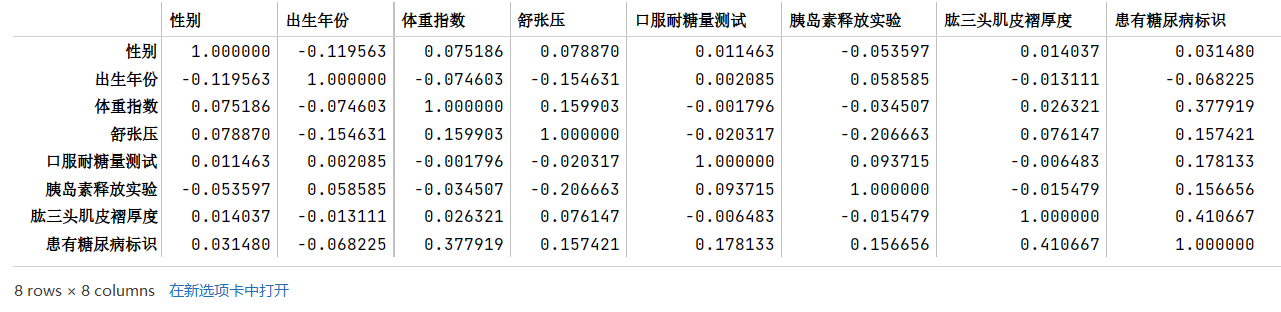
虽然获得了相关系数矩阵,但是不便于分析结果,将其进行可视化,使用seaborn绘制热力图
from string import ascii_lettersimport numpy as npimport pandas as pdimport seaborn as snsimport matplotlib.pyplot as pltsns.set_theme(style="white")plt.rcParams['font.sans-serif'] = ['SimHei'] # 黑体plt.rcParams['axes.unicode_minus']=False # 负号# Generate a mask for the upper trianglemask = np.triu(np.ones_like(corr, dtype=bool))# Set up the matplotlib figuref, ax = plt.subplots(figsize=(8, 8))# Generate a custom diverging colormapcmap = sns.diverging_palette(230, 20, as_cmap=True)# Draw the heatmap with the mask and correct aspect ratiosns.heatmap(corr, mask=mask, cmap=cmap, vmax=0.5, center=0, vmin=-0.3,square=True, linewidths=2, cbar_kws={"shrink": .5})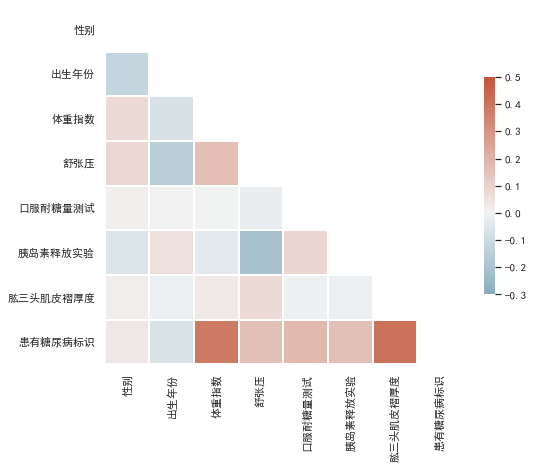
颜色越深,表示和标签的相关性最高,也就是可以重点关注一下体重指数和肱三头肌褶厚度。
同时,还对不同的自变量之间进行相关性分析,按照是否有患有糖尿病标识绘制多变量联合分布pairplot图
sns.set_theme(style="ticks")plt.rcParams['font.sans-serif'] = ['SimHei'] # 黑体plt.rcParams['axes.unicode_minus']=False # 负号sns.pairplot(train_df.drop(columns=['编号','性别']), hue='患有糖尿病标识',plot_kws={'alpha': 0.5})
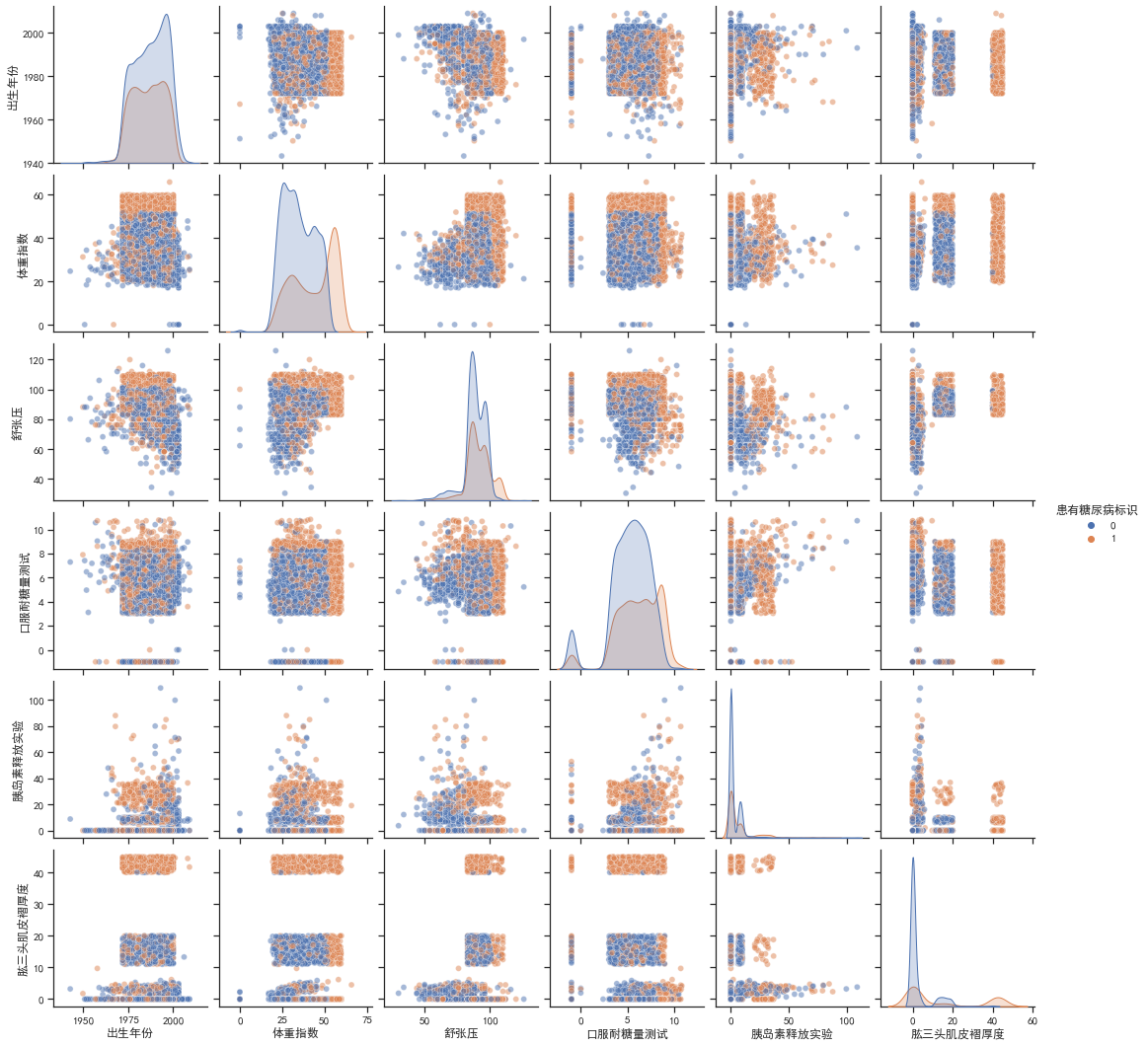
由对角线可知,患有糖尿病和非患者的体重指数和肱三头肌褶厚度的分布有较大差别,患有糖尿病的分布都略向右偏移。由其他子图可知,患者的一些联合分布特征聚集比较紧密,有一些数据还有明显的中断、不连续,可以将其作为类别特征处理,如肱三头肌褶厚度,如果在40以上就极有可能是患者,这样处理可以提高准确率。
任务3:逻辑回归尝试
- 步骤1:导入sklearn中的逻辑回归;
- 步骤2:使用训练集和逻辑回归进行训练,并在测试集上进行预测;
# 预处理(文字转编码、消除nan)train_df.loc[train_df.糖尿病家族史 == '无记录','糖尿病家族史'] = 0train_df.loc[train_df.糖尿病家族史 == '叔叔或姑姑有一方患有糖尿病','糖尿病家族史'] = 1train_df.loc[train_df.糖尿病家族史 == '父母有一方患有糖尿病','糖尿病家族史'] = 2
test_df.loc[test_df.糖尿病家族史 == '无记录','糖尿病家族史'] = 0test_df.loc[test_df.糖尿病家族史 == '叔叔或者姑姑有一方患有糖尿病','糖尿病家族史'] = 1test_df.loc[test_df.糖尿病家族史 == '叔叔或姑姑有一方患有糖尿病','糖尿病家族史'] = 1test_df.loc[test_df.糖尿病家族史 == '父母有一方患有糖尿病','糖尿病家族史'] = 2
pressure_average = sum(train_df.loc[train_df["舒张压"].notnull(),"舒张压"].tolist())/len(train_df.loc[train_df["舒张压"].notnull()])train_df.loc[train_df["舒张压"].isnull(),"舒张压"] = pressure_averagetrain_df
test_df.loc[test_df["舒张压"].isnull(),"舒张压"] = pressure_averagetest_df
# 开始训练from sklearn import linear_model
train_X, train_y = train_df.iloc[:, 1:-1].values, train_df.iloc[:, -1].valuestest_X = test_df.iloc[:, 1:].valueslr = linear_model.LogisticRegression(random_state=42, max_iter=200).fit(train_X, train_y)
# lr.predict_proba(train_X) # 可以获得每个预测的分数lr.score(train_X, train_y) # 0.8122287968441815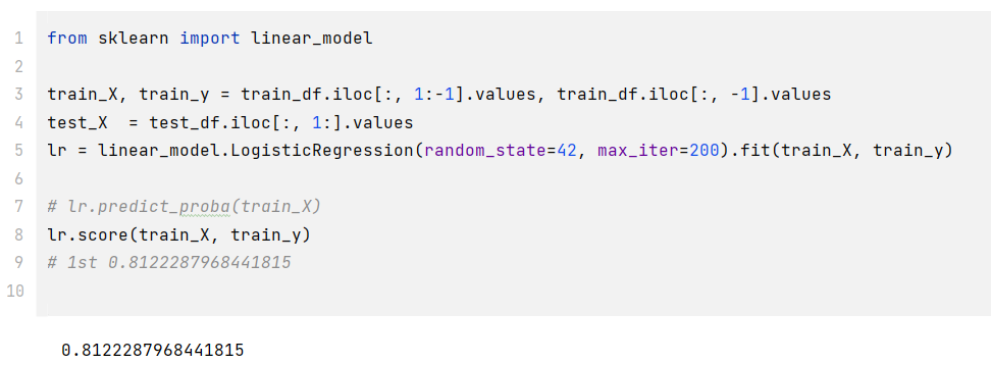
- 步骤3:将步骤2预测的结果文件提交到比赛,截图分数
df = pd.DataFrame(enumerate(test_y,1), columns=['uuid','label'])df.to_csv('0713-hjy.csv', index=False)
- 步骤4:将训练集20%划分为验证集,在训练部分进行训练,在测试部分进行预测,调节逻辑回归的超参数
from sklearn.utils import shuffle
index = int(len(train_df)*0.8)train_df = shuffle(train_df)train_X, train_y = train_df.iloc[:index, 1:-1].values, train_df.iloc[:index, -1].valuesval_X, val_y = train_df.iloc[index:, 1:-1].values, train_df.iloc[index:, -1].valueslr1 = linear_model.LogisticRegression(random_state=42, max_iter=150, C=100).fit(train_X, train_y)lr1.score(val_X, val_y)# 直接分割 0.8126232741617357 0.7938856015779092 0.8353057199211046 无明显变化- 步骤5:如果精度有提高,则重复步骤2和步骤3;如果没有提高,可以尝试树模型,重复步骤2、3
from sklearn.ensemble import RandomForestClassifier # 使用随机森林
index = int(len(train_df)*0.8)train_df = shuffle(train_df)train_X, train_y = train_df.iloc[:index, 1:-1].values, train_df.iloc[:index, -1].valuesval_X, val_y = train_df.iloc[index:, 1:-1].values, train_df.iloc[index:, -1].valueslr2 = RandomForestClassifier(n_estimators=50).fit(train_X, train_y) #参数50lr2.score(val_X, val_y)# 随机森林 0.9615384615384616 0.9575936883629191 0.9694280078895463 很可以了提交一波

任务4:特征工程
- 步骤1:统计每个性别对应的【体重指数】、【舒张压】平均值(后面重做的时候最后发现体重指数有等于0的情况,实际上没有意义,应该设置为中位数或者平均数比较合适)
index = int(len(train_df)*0.8)train_df = shuffle(train_df)
# groupby真好用woman_BMI_average, man_BMI_average = train_df.groupby('性别').mean()['体重指数']woman_pressure_average, man_pressure_average = train_df.groupby('性别').mean()['舒张压']woman_BMI_average, man_BMI_average, woman_pressure_average, man_pressure_average
- 步骤2:计算每个患者与每个性别平均值的差异
train_df['BMI_delta'] = 0train_df['pressure_delta'] = 0
for i in range(len(train_df)): if train_df.iloc[i, 1] == 0: if train_df['体重指数'][i] == 0: train_df['体重指数'][i] = woman_BMI_average train_df['BMI_delta'][i] = train_df['体重指数'][i] - woman_BMI_average train_df['pressure_delta'][i] = train_df['舒张压'][i] - woman_pressure_average else: if train_df['体重指数'][i] == 0: train_df['体重指数'][i] = man_BMI_average train_df['BMI_delta'][i] = train_df['体重指数'][i] - man_BMI_average train_df['pressure_delta'][i] = train_df['舒张压'][i] - man_pressure_average
train_df
test_df['BMI_delta'] = 0test_df['pressure_delta'] = 0
for i in range(len(test_df)): if test_df.iloc[i, 1] == 0: if test_df['体重指数'][i] == 0: test_df['体重指数'][i] = woman_BMI_average test_df['BMI_delta'][i] = test_df['体重指数'][i] - woman_BMI_average test_df['pressure_delta'][i] = test_df['舒张压'][i] - woman_pressure_average else: if test_df['体重指数'][i] == 0: test_df['体重指数'][i] = man_BMI_average test_df['BMI_delta'][i] = test_df['体重指数'][i] - man_BMI_average test_df['pressure_delta'][i] = test_df['舒张压'][i] - man_pressure_average
test_df
- 步骤3:在上述基础上将训练集20%划分为验证集,使用逻辑回归完成训练,精度是否有提高?
from sklearn.metrics import f1_scoretrain_y = train_df.iloc[:index, -3].valuesval_y = train_df.iloc[index:, -3].valuestrain_edit_df = train_df.drop(columns='患有糖尿病标识')train_X = train_edit_df.iloc[:index, 1:].valuesval_X = train_edit_df.iloc[index:, 1:].values
test_X = test_df.iloc[:, 1:].values
# lr3 = linear_model.LogisticRegression(random_state=42, max_iter=1000, C=100).fit(train_X, train_y)# lr3.score(val_X, val_y) #0.8274161735700197 对于逻辑回归变化不大
clf2 = RandomForestClassifier(n_estimators=30).fit(train_X, train_y) #参数30val_y_predict = clf2.predict(val_X)# clf2.score(val_X, val_y) #0.9635108481262328f1_score(val_y, val_y_predict) # 0.9488859764089121
- 步骤4:思考字段含义,尝试新的特征
from sklearn.metrics import f1_score
train_y = train_df.iloc[:index, -5].valuesval_y = train_df.iloc[index:, -5].valuestrain_edit_df = train_df.drop(columns='患有糖尿病标识')train_X = train_edit_df.iloc[:index, 1:].valuesval_X = train_edit_df.iloc[index:, 1:].values
test_X = test_df.iloc[:, 1:].values
# lr4 = linear_model.LogisticRegression(random_state=42, max_iter=5000, C=10).fit(train_X, train_y)# lr4.score(val_X, val_y) #0.8441814595660749 逻辑回归有部分提高
clf3 = RandomForestClassifier(n_estimators=50).fit(train_X, train_y) #参数50val_y_predict = clf3.predict(val_X)# clf3.score(val_X, val_y) # 0.965483234714004f1_score(val_y, val_y_predict) # 0.9502617801047121
def depth_type(depth): if depth < 10: return 0 elif depth < 40: return 1 else: return 2
def BMI_type(bmi): if bmi <= 18.4: return 0 elif bmi <= 23.9: return 1 elif bmi <= 27.9: return 2 else: return 3# 偏瘦 <= 18.4# 正常 18.5 ~ 23.9# 过重 24.0 ~ 27.9# 肥胖 >= 28.0
train_df['bmi_type'] = train_df['体重指数'].map(lambda x: BMI_type(x))train_df['depth_type'] = train_df['肱三头肌皮褶厚度'].map(lambda x: depth_type(x))train_df
test_df['bmi_type'] = test_df['体重指数'].map(lambda x: BMI_type(x))test_df['depth_type'] = test_df['肱三头肌皮褶厚度'].map(lambda x: depth_type(x))test_df
from sklearn.metrics import f1_score
train_y = train_df.iloc[:index, -5].valuesval_y = train_df.iloc[index:, -5].valuestrain_edit_df = train_df.drop(columns='患有糖尿病标识')train_X = train_edit_df.iloc[:index, 1:].valuesval_X = train_edit_df.iloc[index:, 1:].values
test_X = test_df.iloc[:, 1:].values
# lr4 = linear_model.LogisticRegression(random_state=42, max_iter=5000, C=10).fit(train_X, train_y)# lr4.score(val_X, val_y) #0.8353057199211046 逻辑回归有部分提高
clf3 = RandomForestClassifier(n_estimators=50).fit(train_X, train_y) #参数50val_y_predict = clf3.predict(val_X)# clf3.score(val_X, val_y) # 0.97534516765286f1_score(val_y, val_y_predict) # 0.9645390070921985任务5:特征筛选
- 步骤1:使用树模型完成模型的训练,通过特征重要性筛选出Top5的特征;
data={'featureName':train_edit_df.columns[1:],'importances':clf2.feature_importances_.tolist()}df = pd.DataFrame(data)df=df.sort_values(by=['importances'],ascending=False)df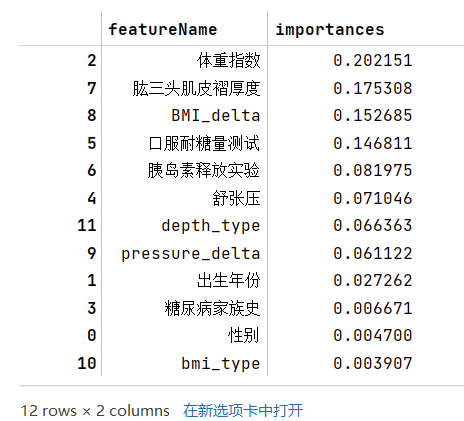
- 步骤2:使用筛选出的特征和逻辑回归进行训练,在验证集精度是否有提高?
train_X = train_df[["体重指数","肱三头肌皮褶厚度","BMI_delta","口服耐糖量测试","胰岛素释放实验"]].iloc[:index, :].valuestrain_y = train_df["患有糖尿病标识"].iloc[:index].valuesval_X = train_df[["体重指数","肱三头肌皮褶厚度","BMI_delta","口服耐糖量测试","胰岛素释放实验"]].iloc[index:, :].valuesval_y = train_df["患有糖尿病标识"].iloc[index:].values
test_X = test_df[["体重指数","肱三头肌皮褶厚度","BMI_delta","口服耐糖量测试","胰岛素释放实验"]].values
# lr5 = linear_model.LogisticRegression(random_state=42, max_iter=500, C=100).fit(train_X, train_y)# lr5.score(val_X, val_y) #0.8274161735700197 逻辑回归下降了
clf4 = RandomForestClassifier(n_estimators=50).fit(train_X, train_y) #参数50val_y_predict = clf4.predict(val_X)# clf4.score(val_X, val_y) #0.9368836291913215 也下降了f1_score(val_y, val_y_predict) # 0.9058823529411766-
步骤3:如果有提高,为什么?如果没有提高,为什么?
没有提高,其他特征也比较重要,筛选的特征太少了导致细节丢失,换几个主要特征后,基本回升到原来的状态,应该是到了随机森林模型极限了,修改随机森林的参数也没有太大提升
from sklearn.metrics import f1_score
train_X = train_df[["体重指数","肱三头肌皮褶厚度","BMI_delta","口服耐糖量测试","胰岛素释放实验","舒张压","depth_type"]].iloc[:index, :].valuestrain_y = train_df["患有糖尿病标识"].iloc[:index].valuesval_X = train_df[["体重指数","肱三头肌皮褶厚度","BMI_delta","口服耐糖量测试","胰岛素释放实验","舒张压","depth_type"]].iloc[index:, :].valuesval_y = train_df["患有糖尿病标识"].iloc[index:].values
test_X = test_df[["体重指数","肱三头肌皮褶厚度","BMI_delta","口服耐糖量测试","胰岛素释放实验","舒张压","depth_type"]].values
# lr6 = linear_model.LogisticRegression(random_state=42, max_iter=500, C=100).fit(train_X, train_y)# lr6.score(val_X, val_y) #0.8392504930966469 没有提高#clf5 = RandomForestClassifier(n_estimators=50).fit(train_X, train_y) #参数50val_y_predict = clf5.predict(val_X)# clf5.score(val_X, val_y) # 0.9644970414201184f1_score(val_y, val_y_predict) # 0.9501312335958005任务6:高阶树模型
- 步骤1:安装LightGBM,并学习基础的使用方法
- 步骤2:将训练集20%划分为验证集,使用LightGBM完成训练,精度是否有提高?
import lightgbm as lgb
clf6 = lgb.LGBMClassifier()clf6.fit(train_X, train_y, eval_set=[(val_X,val_y)], callbacks=[lgb.early_stopping(50)])val_y_predict = clf6.predict(val_X)
# clf6.score(val_X, val_y) # 0.9635108481262328f1_score(val_y, val_y_predict) # 0.9512516469038208- 步骤3:将步骤2预测的结果文件提交到比赛,截图分数,没有前面的好

- 步骤4:尝试调节搜索LightGBM的参数
clf7 = lgb.LGBMClassifier( max_depth=2, n_estimators=2000, n_jobs=-1, verbose=-1, learning_rate=0.2,)clf7.fit(train_X, train_y, eval_set=[(val_X,val_y)], callbacks=[lgb.early_stopping(50)])val_y_predict = clf7.predict(val_X)
# clf7.score(val_X, val_y) # 0.960552268244576f1_score(val_y, val_y_predict) # 0.9468085106382979- 步骤5:将步骤4调参之后的模型从新训练,将最新预测的结果文件提交到比赛,寄

任务7:多折训练与集成
- 步骤1:使用KFold完成数据划分
from sklearn.model_selection import KFold
train_X = train_df[["体重指数","肱三头肌皮褶厚度","BMI_delta","口服耐糖量测试","胰岛素释放实验","舒张压","depth_type"]].iloc[:index, :]train_y = train_df["患有糖尿病标识"].iloc[:index]val_X = train_df[["体重指数","肱三头肌皮褶厚度","BMI_delta","口服耐糖量测试","胰岛素释放实验","舒张压","depth_type"]].iloc[index:, :]val_y = train_df["患有糖尿病标识"].iloc[index:]
test_X = test_df[["体重指数","肱三头肌皮褶厚度","BMI_delta","口服耐糖量测试","胰岛素释放实验","舒张压","depth_type"]]
# 模型交叉验证def run_model_cv(model, kf, X_tr, y, X_te, cate_col=None): train_pred = np.zeros( (len(X_tr), len(np.unique(y))) ) test_pred = np.zeros( (len(X_te), len(np.unique(y))) )
cv_clf = [] for tr_idx, val_idx in kf.split(X_tr, y): x_tr = X_tr.iloc[tr_idx]; y_tr = y.iloc[tr_idx] x_val = X_tr.iloc[val_idx]; y_val = y.iloc[val_idx] call_back = [lgb.early_stopping(50),] eval_set = [(x_val, y_val)] model.fit(x_tr, y_tr, eval_set=eval_set, callbacks=call_back) cv_clf.append(model) train_pred[val_idx] = model.predict_proba(x_val) test_pred += model.predict_proba(X_te)
test_pred /= kf.n_splits return train_pred, test_pred, cv_clf
train_pred, test_pred, cv_clf = run_model_cv( clf7, KFold(n_splits=7), train_X, train_y, val_X,)# test_pred
test_pred_arg_max = [ i.argmax() for i in test_pred]f1_score(val_y, val_y_predict) # 0.9522546419098143 没变- 步骤2:使用StratifiedKFold完成数据划分
from sklearn.model_selection import StratifiedKFold
train_pred, test_pred, cv_clf = run_model_cv( clf8, StratifiedKFold(n_splits=10), train_X, train_y, val_X,)# test_pred
test_pred_arg_max = [ i.argmax() for i in test_pred]f1_score(val_y, val_y_predict) # 0.9522546419098143- 步骤3:使用StratifiedKFold配合LightGBM完成模型的训练和预测(如上)
- 步骤4:在步骤3训练得到了多少个模型,对测试集多次预测,将最新预测的结果文件提交到比赛,截图分数,分数没有增长就不截图了
- 步骤5:使用交叉验证训练5个机器学习模型(svm、lr等),使用stacking完成集成,将最新预测的结果文件提交到比赛,截图分数
from sklearn.ensemble import ExtraTreesClassifier, AdaBoostClassifier, GradientBoostingClassifier
#使用random forest、extratrees、adaboost、gradientboosting、svm作为第一层分类器#第二层lgb
# Class to extend the Sklearn classifierclass SklearnHelper(object): def __init__(self, clf, seed=42, params=None): params['random_state'] = seed self.clf = clf(**params)
def train(self, x_train, y_train): self.clf.fit(x_train, y_train)
def predict(self, x): return self.clf.predict(x)
def fit(self,x,y): return self.clf.fit(x,y)
def feature_importances(self,x,y): print(self.clf.fit(x,y).feature_importances_)
#底层模型交叉训练oof
def get_oof(model, kf, X_tr, y, X_te, cate_col=None): train_pred = np.zeros( (len(X_tr), )) test_pred = np.zeros( (len(X_te), )) cv_clf = [] for tr_idx, val_idx in kf.split(X_tr, y): x_tr = X_tr.iloc[tr_idx]; y_tr = y.iloc[tr_idx]
x_val = X_tr.iloc[val_idx]; y_val = y.iloc[val_idx]
model.fit(x_tr, y_tr)
cv_clf.append(model)
train_pred[val_idx] = model.predict(x_val) test_pred += model.predict(X_te)
test_pred /= kf.n_splits return train_pred, test_pred
# Put in our parameters for said classifiers# Random Forest parametersrf_params = { 'n_estimators': 100, 'max_depth': 10, 'min_samples_leaf': 10, 'max_features' : 'sqrt',}
# Extra Trees Parameterset_params = { 'n_jobs': -1, 'n_estimators':500, 'max_depth': 10, 'min_samples_leaf': 10,}
# AdaBoost parametersada_params = { 'n_estimators': 500, 'learning_rate' : 0.015}
# Gradient Boosting parametersgb_params = { 'n_estimators': 500, 'max_depth': 3, 'min_samples_leaf': 2, 'learning_rate': 0.015}
# Support Vector Classifier parameters# svc_params = {# 'kernel' : 'linear',# 'C' : 0.02# }
# Create 5 objects that represent our 5 modelsrf = SklearnHelper(clf=RandomForestClassifier, seed=2022, params=rf_params)et = SklearnHelper(clf=ExtraTreesClassifier, seed=2022, params=et_params)ada = SklearnHelper(clf=AdaBoostClassifier, seed=2022, params=ada_params)gb = SklearnHelper(clf=GradientBoostingClassifier, seed=2022, params=gb_params)# svc = SklearnHelper(clf=SVC, seed=2022, params=svc_params)
# Create our OOF train and test predictions. These base results will be used as new featureskf = KFold(n_splits=5)
rf_oof_train, rf_oof_test = get_oof(rf, kf, train_X, train_y, val_X) # Random Forestet_oof_train, et_oof_test = get_oof(et, kf, train_X, train_y, val_X) # Extra Treesada_oof_train, ada_oof_test = get_oof(ada,kf, train_X, train_y, val_X) # AdaBoostgb_oof_train, gb_oof_test = get_oof(gb, kf, train_X, train_y, val_X) # Gradient Boost# svc_oof_train, svc_oof_test = get_oof(svc,kf, train_X, train_y, val_X) # Support Vector Classifier
print("Training is complete")
#第二层的训练及验证数据base_predictions_train = pd.DataFrame({ 'RandomForest': rf_oof_train.ravel(), 'ExtraTrees': et_oof_train.ravel(), 'AdaBoost': ada_oof_train.ravel(), 'GradientBoost': gb_oof_train.ravel(), # 'Svc': svc_oof_train.ravel()})
base_predictions_test = pd.DataFrame({ 'RandomForest': rf_oof_test.ravel(), 'ExtraTrees': et_oof_test.ravel(), 'AdaBoost': ada_oof_test.ravel(), 'GradientBoost': gb_oof_test.ravel(), # 'Svc': svc_oof_test.ravel()})
clf8 = lgb.LGBMClassifier( # boosting_type='gbdt', # objective='binary', # metrics='binary_logloss', # learning_rate=0.015, # n_estimators=500, # max_depth=3, # num_leaves=10, # max_bin=200, # min_data_in_leaf=101, # bagging_fraction=0.8, # bagging_freq= 0, # feature_fraction= 0.8, # lambda_l1=0.7, # lambda_l2=0.7, # min_split_gain=0.1,)
clf8.fit(base_predictions_train, train_y)f1_score(clf8.predict(base_predictions_test),val_y)# test_df['label'] = clf.predict(base_predictions_test)# test_df.rename({'编号': 'uuid'}, axis=1)[['uuid', 'label']].to_csv('submit.csv', index=None)
#改
from sklearn.ensemble import ExtraTreesClassifier, AdaBoostClassifier, GradientBoostingClassifier
#使用random forest、extratrees、adaboost、gradientboosting、svm作为第一层分类器#第二层lgb
train_X = train_df[["体重指数","肱三头肌皮褶厚度","BMI_delta","口服耐糖量测试","胰岛素释放实验","舒张压","depth_type"]]train_y = train_df["患有糖尿病标识"]
test_X = test_df[["体重指数","肱三头肌皮褶厚度","BMI_delta","口服耐糖量测试","胰岛素释放实验","舒张压","depth_type"]].iloc[:]
kf = KFold(n_splits=5)
rf_oof_train, rf_oof_test = get_oof(rf, kf, train_X, train_y, test_X) # Random Forestet_oof_train, et_oof_test = get_oof(et, kf, train_X, train_y, test_X) # Extra Treesada_oof_train, ada_oof_test = get_oof(ada,kf, train_X, train_y, test_X) # AdaBoostgb_oof_train, gb_oof_test = get_oof(gb, kf, train_X, train_y, test_X) # Gradient Boost# svc_oof_train, svc_oof_test = get_oof(svc,kf, train_X, train_y, val_X) # Support Vector Classifier
print("Training is complete")
#第二层的训练及验证数据base_predictions_train = pd.DataFrame({ 'RandomForest': rf_oof_train.ravel(), 'ExtraTrees': et_oof_train.ravel(), 'AdaBoost': ada_oof_train.ravel(), 'GradientBoost': gb_oof_train.ravel(), # 'Svc': svc_oof_train.ravel()})
base_predictions_test = pd.DataFrame({ 'RandomForest': rf_oof_test.ravel(), 'ExtraTrees': et_oof_test.ravel(), 'AdaBoost': ada_oof_test.ravel(), 'GradientBoost': gb_oof_test.ravel(), # 'Svc': svc_oof_test.ravel()})
clf9 = lgb.LGBMClassifier()
clf9.fit(base_predictions_train, train_y)test_y = clf9.predict(base_predictions_test)test_y
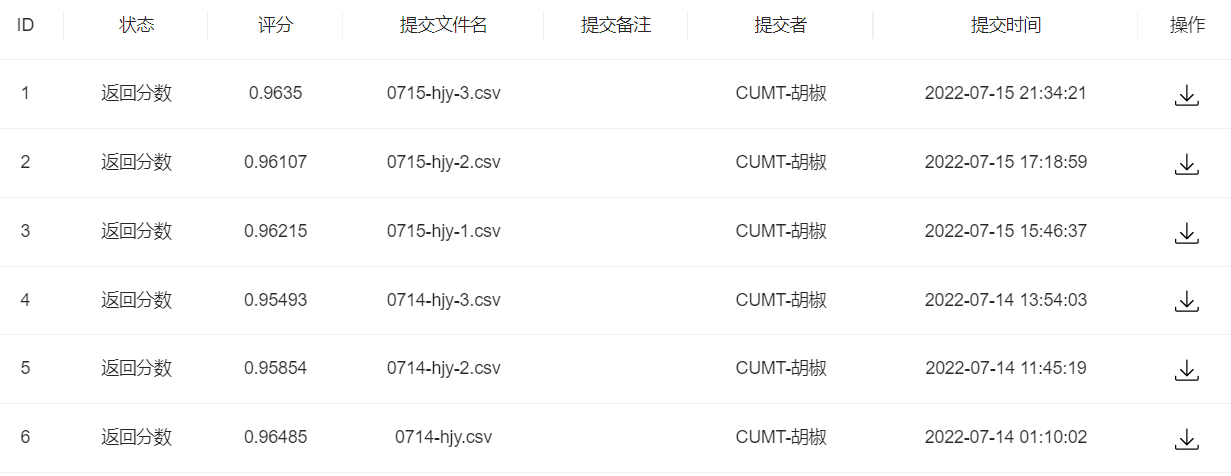
df = pd.DataFrame(enumerate(test_y,1), columns=['uuid','label'])df.to_csv('0715-hjy-3.csv', index=False)蚌埠住了,集成学习了之后还没不集成和不特征工程的分数高,傻了。
Comments