和鲸社区2022咸鱼打挺夏令营-机器学习原理与实践·闯关-作业答案与部分解析
本文最后更新于:2022年9月13日 07:55
第一关 - 逻辑回归
作业
作业1:逻辑回归的表达式:
A: h(x)=wx+b
B:h(x)=wx
C: h(x)=sigmoid(wx+b)
D: h(x)=sigmoid(wx)
作业2:下面关于逻辑回归的表述是正确的(多选):
A:逻辑回归的输出结果是概率值,在0-1之间
B:使用正则化可以提高模型的泛化性
C:逻辑回归可以直接用于多分类
D:逻辑回归是无参模型
E:逻辑回归的损失函数是交叉熵
作业3:计算 $y=sigmoid(w_1x_1+w_2x_2+1)$ 当 w=(0.2, 0.3)时,样本X=(1,1),y=1的时w1,w2的梯度和loss:(保存3位小数,四舍五入)
作业4:在cal_grad梯度函数的基础上加上L2正则化,下面的函数是否正确?(Y/N)
1
2
3
4
5
6
7
8
9def cal_grad(y, t,x,w):
"""
x:输入X
y:样本y
t:预测t
w:参数w
"""
grad = np.sum(t - y) / t.shape[0]
return grad*x+2*w
答案
| id | answer | |
|---|---|---|
| 0 | a1 | C |
| 1 | a2 | ABE |
| 2 | a3 | -0.182 |
| 3 | a4 | -0.182 |
| 4 | a5 | 0.201 |
| 5 | a6 | Y |
解析
t1代码
1 | |
第二关 - 朴素贝叶斯法
作业
1:假设A,B两个盒子球有无限个,已知从A盒子摸出红球和白球的概率为0.7和0.3,从B盒子中摸出的红球和白球的概率为0.5和0.5。从某一个盒子中摸了3次球,颜色依次为白,白,红。问是从A盒子中摸得的概率是多少?(保留4位小数)
2:贝叶斯推断最重要的假设是什么?
A:独立性假设
B:参数服从一个分布
3:贝叶斯估计与最大似然估计的区别是:(Y/N)
贝叶斯假设参数服从一个分布,不是一个确定的值,而最大似然估计认为参数是一个值。
4:假设训练数据:确定 x=(2,S) 的结果,求出y的预测结果
1
2
3
4X=[["1","S"],["1","M"],["1","M"],["1","S"],["1","S"],\
["2","S"],["2","M"],["2","M"],["2","L"],["2","L"],\
["3","L"],["3","M"],["3","M"],["3","L"],["3","L"]]
Y=[0,0,1,1,0,0,0,1,1,1,1,1,1,1,0]5:第四题中,当使用拉普拉斯平滑,即λ=1,求y的预测结果
答案
| id | answer | |
|---|---|---|
| 0 | a1 | 0.3351 |
| 1 | a2 | A |
| 2 | a3 | Y |
| 3 | a4 | 0 |
| 4 | a5 | 0 |
解析
t1解法
1 | |
t4解法:看统计学习方法,原题
题目讲解来源:【合集】十分钟 机器学习 系列视频 《统计学习方法》

t5看公式
当$\lambda$等于1的时候,称之为拉普拉斯平滑。
p(y=1)=(9+1)/(15+2)
p(y=0)=(6+1)/(15+2)
第三关 - K近邻算法
作业
1:请你回顾下KNN算法的三要素:
2:改写一下函数使其可以应用于KNN的回归预测,回归预测的loss为平方差
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28def predict(self, train_x, y, test, k):
"""
返回根据KNN预测的结果
:param train_x: 训练集x
:param y: 训练集y
:param test: 预测集
:return: 返回test预测的结果
"""
dis = self.euclidean_dis(test, train_x)
k_neighbor = np.argsort(dis, axis=1)[:, :k]
k_neighbor_value = y[k_neighbor]
n = test.shape[0] # 预测结果的个数
pred = np.zeros(n)
for i in range(n):
pred[i] = np.argmax(np.bincount(k_neighbor_value[i])) ##改写1
return pred
def KFlod(self, k):
folds = StratifiedKFold(n_splits=5, shuffle=True, random_state=1996)
oof = np.zeros(self.train_x.shape[0])
for fold_, (train_index, test_index) in enumerate(folds.split(self.train_x, self.train_y)):
train_x, test_x, train_y, test_y = self.train_x[train_index], self.train_x[test_index], \
self.train_y[
train_index], self.train_y[test_index]
pred = self.predict(train_x, train_y, test_x, k)
oof[test_index] = pred
return np.sum(oof == self.train_y) #改写2下面那个改写是正确的:
A:pred[i]=np.sum(k_neighbor_value[i]),np.sum(oof - self.train_y)
B: pred[i]=np.mean(k_neighbor_value[i]),np.sum(oof - self.train_y)
C:pred[i]=np.sum(k_neighbor_value[i]),np.sum((oof - self.train_y)**2)
D: pred[i]=np.mean(k_neighbor_value[i]),np.sum((oof - self.train_y)**2)
3:使用全部iris数据,选取中最优的K值,并且计算此时分类正确的个数
答案
| id | answer | |
|---|---|---|
| 0 | a1 | K值 |
| 1 | a2 | 度量距离 |
| 2 | a3 | 决策规则 |
| 3 | a4 | D |
| 4 | a5 | 13 |
| 5 | a6 | 146 |
解析
t3代码
1 | |
第四关 - K-means算法
题目
数据准备
1 | |
- 1.对样本X进行归一化(均值方差归一化),输出并且将归一化的结果的第一行(将输出的list转化为string,用逗号(,)连接,四舍五入保留3位小数,注意不能有空格)
- 2:计算上一步归一化之后样本中第一个样本与最后一个样本的欧式距离(四舍五入3位小数)。
- 3:根据数据中已有的类别(Y就是类别),分别计算类别0,类别1,类别2的中心点(不归一化):(将输出的list转化为string,用逗号(,)连接,四舍五入保留1位小数,不能有空格)
答案
| id | answer | |
|---|---|---|
| 0 | a1 | -0.901,1.019,-1.340,-1.315 |
| 1 | a2 | 3.335 |
| 2 | a3 | 5.0,3.4,1.5,0.2 |
| 3 | a4 | 5.9,2.8,4.3,1.3 |
| 4 | a5 | 6.6,3.0,5.6,2.0 |
解析
题目1
1 | |
题目2
1 | |
题目3(不要看错题目认为是根据kmeans计算得到聚类中心点,而是根据已有标签计算中心点)
1 | |
第五关 - 线性判别器LDA
题目
1:在2.2(扩展到多分类)中说到,”两种计算方式的结果是成比例的”,请你计算一下使用我们代码中计算方法和采用另外一种方法计算两者之间的比例。$SB1$为我给出代码中的计算方法,$S_B2$为$S_b=\sum{i,j|i\neq j}[(u_i-u_j)(u_i-u_j)^T]$,直接给出$S_B1$与$S_B2$之间的比例。
2:下面关于线性判别器的理解正确的是?(不定项)
A:线性判别器是一个分类器
B:线性判别器是一个无监督模型
C:线性判别器是一个降维方法
D:线性判别器可以降低至任意维度
答案
| id | answer | |
|---|---|---|
| 0 | a1 | 8.33 |
| 1 | a2 | C |
解析
t1代码
1 | |
第六关 - 支持向量机
题目
1:下面逻辑回归与支持向量机的对比正确的是:(多选,注意大写)
A:逻辑回归速度比SVM更快
B:SVM和逻辑回归一样,任何样本都会对最终情况产生影响
C:都不能直接进行多分类
D:逻辑回归输出概率,SVM直接输出类别
E:两者的目标函数不同,逻辑回归是交叉熵,SVM是Hinge Loss
2:关于选取最大分离面下面说法是否正确?(Y/N)
回答:理论上来说,分离超平面有无数个,但是最大分离面只有一个。此外,使用最大间隔分离面对未知的样本有更好的泛化能力。
3:下面关于核函数的介绍正确的是?(多选,注意大写)
A:提升SVM的非线性拟合能力
B:可以提升SVM模型的准确度
C:能够使得模型训练速度变快
D:降低模型过拟合的风险
答案
| id | answer | |
|---|---|---|
| 0 | a1 | ACDE |
| 1 | a2 | Y |
| 2 | a3 | AB |
第七关 - 决策树
题目
1:写出文中介绍的三种分类算法(按照介绍的顺序)
2:计算下面数据的熵与Gini指数(保留3位小数,四舍五入)
1
2
3import pandas as pd
data_path=r"/home/mw/input/data2794"
data = pd.read_csv(r"/home/mw/input/data2794/西瓜数据集.csv")
答案
| id | answer | |
|---|---|---|
| 0 | a1 | 信息增益 |
| 1 | a2 | 信息增益比 |
| 2 | a3 | Gini指数 |
| 3 | a4 | 0.998 |
| 4 | a5 | 0.498 |
解析
t2代码
1 | |
第八关 - 基于xgboost的分类预测
题目
1:xgb与GBDT在损失函数上的区别(多选)
A:正则化
B:二阶残差
C:一阶残差
2:计算函数 f=x3+x2 在x=0.5处的二阶梯度
3:下面哪些方式可以提升xgb模型的准确度(多选)
A:更多的数据
B:更好的特征工程
C:减少树的深度
D:增加学习率
4:令x=x_train[:1],使用上面的sklearn包装的xgb模型预测x所对应得target值(输出target为1概率,保留4位小数)
答案
| id | answer | |
|---|---|---|
| 0 | a1 | AB |
| 1 | a2 | 5 |
| 2 | a3 | ABCD |
| 3 | a4 | 0.0307 |
解析
t4代码
1 | |
关卡9 基于LightGBM的数据实践
1:下面哪些是lgb相对于xgb的优化点?
A:使用了二阶残差
B:使用了直方图进行加速计算
C:可以支持类别特征处理
D:使用了单边梯度采样减少计算样本
E:使用了互斥捆绑算法进行特征组合减少了特征数量
F:使用了带深度限制的 Leaf-wise 算法避免了无效的树生长
2:假设叶节点的数量相同,xgb的深度一定会比lgb的深度大?(Y/N)
3:下面关于lgb与随机森林的说法正确的是(多选)?
A:lgb和随机森林都是由多颗决策树组成
B:Lgb和随机森林的树都是可以并行生成的
C:随机森林的决策树可以是回归树也可以是分类树,lgb只能是回归树
D:随机森林主要是通过减低方差提高模型的泛化能力,lgb是降低偏差提高模型的拟合能力
答案
| id | answer | |
|---|---|---|
| 0 | a1 | BCDEF |
| 1 | a2 | N |
| 2 | a3 | ACD |
关卡10 BP神经网络
题目
1:BP神经网络过拟合时可以通过哪些方法来改进
A:减少网络深度
B:减少神经元的数量
C:增加dropout
D:增加数据量
2:当进行回归预测时,计算输出层的loss和回传梯度
t=np.array([[0.00324988]
[0.01669568]
[0.01676606]
[0.97652019]])y=np.array([[0],[0],[0],[1]])
提交结果格式为:0.3,0.2,0.2,0.4,0.5
前四个数字为梯度,第五个为loss,保留5位小数(四舍五入,请注意不要有空格)以上面的神经网络为例,请问一下总共的参数数量为多少?答案为整数
使用上面的神经网络预测test=[[0.3,0.4],[1,2]]的类别。输出结果为(两个结果直接相连,比如提交01,11,10等)
答案
| id | answer | |
|---|---|---|
| 0 | a1 | ABCD |
| 1 | a2 | 0.00325,0.01670,0.01677,-0.02348,0.01519 |
| 2 | a3 | 17 |
| 3 | a4 | 01 |
解析
t2代码
1 | |
t3
包括w和b
一层2->4 2*4+4=12
一层4->1 4*1+1=5
12+5=17个
t4代码
1 | |
模型
1 | |
大作业:疾病预测
使用欠采样处理正负样本不能不均衡(0.816)
1 | |
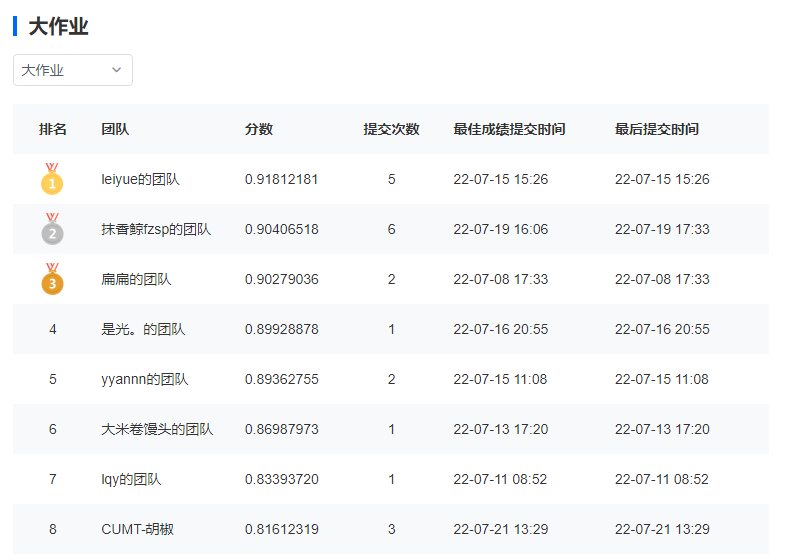
使用欠采样、模拟voting(0.834)
1 | |