本文最后更新于:2024年8月21日 20:26
记录 8.21调整学习率跑baseline,线下f1macro和acc非常高甚至99,但是线上反而降了,考虑可能过拟合了,从训练数据上入手先分析数据
可以看标签名称和图像有关联,应该是来自于同一个视频,做了帧采样
还有个数据名称是
一看就是想打括号忘记加shift了
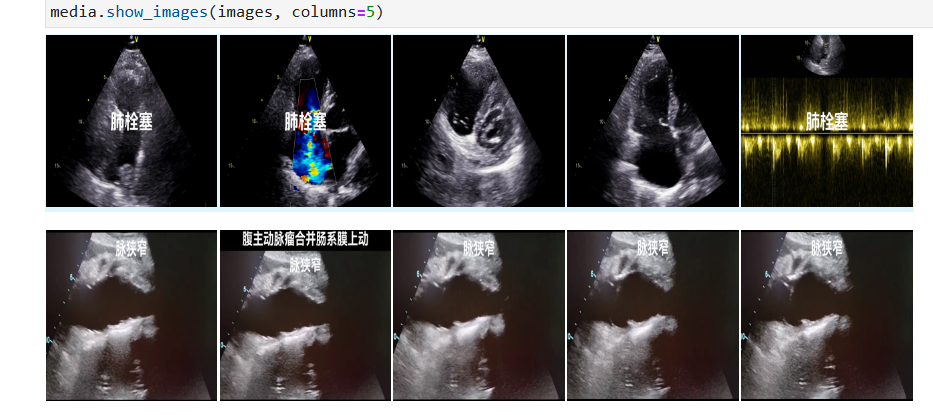
还有一堆重复的图,基本上没有什么变化,感觉是复制粘贴的,比如这个DCM的,就没动静,我觉得应该清洗掉,肯定是训练的时候这个太关注这个地方了
测试集也是也有一样的图
可以先做个聚类,把一样的图聚类在一起然后给一样的标签(要么都对了要么都寄了)
训练集有非医学影像 删除 ./data/train/Cyst/04/*.npy
没有内容的也要删除 ./data/train/Vascular/01/*.npy”
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 import numpy as npimport mediapy as mediaimport glob, osfor i in range (1 ,12 ):sorted (glob.glob(f"./data/train/Anomalies/{i:02} /*.npy" ))print (i)for image_path in image_paths:10 )"Anomalies" : 11 ,"Cyst" : 11 ,"Inflammation" : 11 ,"Tumor" : 13 ,"Vascular" : 11 import torchimport torch.nn as nnimport torchvision.models as modelsimport torchvision.transforms as transformsfrom PIL import Imageclass DemoNet (nn.Module ):def __init__ (self ):super (DemoNet, self).__init__()True )def forward (self, img ):return outeval ()256 , 256 )),with torch.no_grad():for idx, class_name in enumerate (train_class_and_folder_num):for i in range (1 , folder_num+1 ):sorted (glob.glob(f"./data/train/{class_name} /{i:02} /*.npy" ))for image_path in image_paths:0 ).cuda()0 )f"./data/train_class_{idx} .pt" , features)