基于Unet3p的车道中线检测模型 - 航天智慧物流2022
本文最后更新于:2022年9月13日 07:54
参考资料
理论基础
Unet基本结构
第一部分是主干特征提取部分,我们可以利用主干部分获得一个又一个的特征层,Unet的主干特征提取部分与VGG相似,为卷积和最大池化的堆叠。利用主干特征提取部分我们可以获得五个初步有效特征层,在第二步中,我们会利用这五个有效特征层可以进行特征融合。
第二部分是加强特征提取部分,我们可以利用主干部分获取到的五个初步有效特征层进行上采样,并且进行特征融合,获得一个最终的,融合了所有特征的有效特征层。
第三部分是预测部分,我们会利用最终获得的最后一个有效特征层对每一个特征点进行分类,相当于对每一个像素点进行分类。


- Dice loss将语义分割的评价指标作为Loss,Dice系数是一种集合相似度度量函数,通常用于计算两个样本的相似度,取值范围在[0,1]。就是预测结果和真实结果的交乘上2,除上预测结果加上真实结果。其值在0-1之间。越大表示预测结果和真实结果重合度越大。所以Dice系数是越大越好。
UNet3p
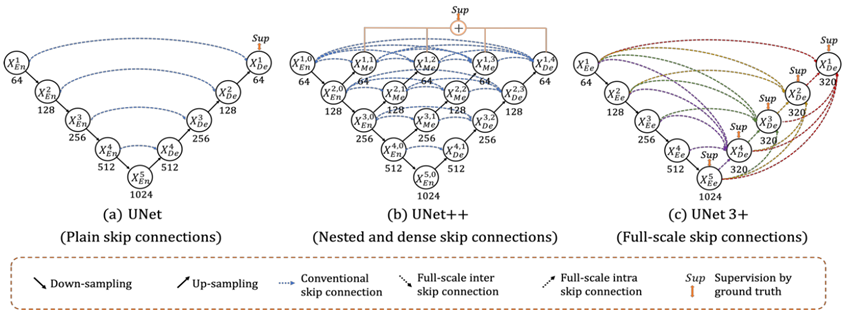
UNET3+的提出旨在充分利用多尺度特征,相较于U-NET和U-NET++, U-Net3+通过一种新的基于u型的体系结构结合了多尺度特征,重新设计了编码器和解码器与解码器之间的跳跃连接,能够从全尺度获取细粒度细节和粗粒度细节,并利用多尺度的深度监督,使得每一边的输出都能与一个混合损失函数连接,有助于精确分割。同时,UNet 3+可以减少网络参数,提高计算效率。
结构
全尺寸跳跃连接(Full-scale Skip Connnections)
全尺寸跳跃连接使得UNET3+中每一个解码器层都融合了来自编码器的小尺度和同尺度的特征图,以及来自解码器的大尺度的特征图,以此捕获了全尺度下的粗、细粒度语义。
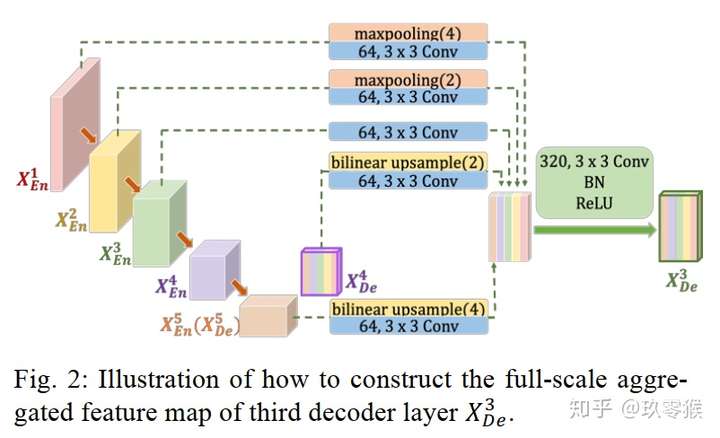
例如,图2说明了如何构造$X{De}^3$特征图。与UNet类似,直接接收来自相同尺度编码器层的特征图$X{En}^3$。但不同的是,跳跃连接不止上面一条。
- 上方:其中,上面两条跳跃连接通过不同的最大池化操作将较小尺度编码器层$X{En}^1$和$X{En}^2$进行池化下采样,以便传递底层的低级语义信息。之所以要池化下采样,是因为要统一特征图的分辨率。从图中可知,$X{En}^1$要缩小分辨率4倍,$X{En}^2$要缩小分辨率2倍。
- 下方:另外的下面两条跳跃连接则通过双线性插值法对解码器中的$X{En}^4$和$X{En}^5$进行上采用从而放大特征图的分辨率,从图中可知,$X{En}^5$($X{De}^5$)要放大分辨率4倍,$X_{En}^4$要放大分辨率2倍。
- 双线性插值是分别在两个方向计算了共3次单线性插值(x轴两次、y轴一次),可以先在x方向求2次单线性插值,获得两个临时点,再在y方向计算1次单线性插值得出(实际上调换2次轴的方向先y后x也是一样的结果)
- 统一完特征图之后,还不能结合它们,还需要统一特征图的数量,减少多余的信息。作者发现64个3×3大小的滤波器进行卷积表现效果较好,卷积后便产生64个通道的特征图
- 统一好了feature map的分辨率和数量后,就可以将浅层的精细信息与深层的语义信息进行特征融合了,关于特征融合一般有如下两种方法,FCN式的逐点相加或者U-Net式的通道维度拼接融合,本文是后者。这5个尺度融合后,便产生5*64=320个相同分辨率的特征图,然后再经过320个3×3大小的滤波器进行卷积 ,最后再经过BN + ReLU得到$X_{De}^3$。
全尺寸深度监督(Full-scale Deep Supervision)
全尺寸深度监督度生成的全分辨率特征图进行深度监督,在各个尺度连接后加一个1×1的卷积核,以此监督每个分支的UNET输出。
为了从全尺度的聚合特征图中学习层次表示,UNet 3+进一步采用了全尺度深度监督。不同于UNet++,UNet 3+中每个解码器阶段都有一个侧输出,是金标准(ground truth,GT)进行监督。为了实现深度监督,每个解码器阶段的最后一层被送入一个普通的3×3卷积层,然后是一个双线性上采样和一个sigmoid函数。(这里的上采样是为了放大到全分辨率)。
分类指导模块(Classification-guided Module, CGM)
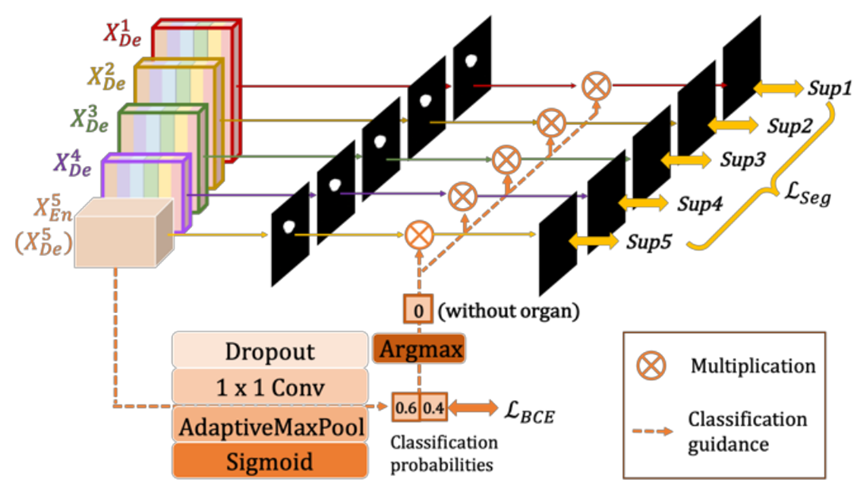
在车道线检测过程中,由赛道边界线和地面影响,分割图像出现假阳性是不可避免的。与此类似,UNET3+针对预测输入图像是否是车道线而设计的分类指导模块增加了一个额外的分类任务来解决背景噪声导致分割停留在较浅的层次,过度分割的现象。
最深层次的二维张量$X_{En}^5$依次经过dropout,卷积,maxpooling,sigmoid, 最后输出有车道线的概率。由于二值分类任务的简单性,该模块通过优化二值交叉熵损失函数,轻松获得准确的分类结构,实现对非车道线图像过分割的指导。
项目实践
获取照片
队友手动拍摄的290张S弯车道照片(白天、夜间均有)

标注
使用labelme对车道线进行标注

生成数据集、格式转换、分割
将img.png使用opencv根据传统图像处理方法进行二值化,训练集和验证集为262/29

二值化
使用YCrCb颜色格式,只取minYCB和maxYCB中间的区域,使用THRESH_BINARY进行二值化
1 | |
训练
参数
loss为二分类交叉熵损失,优化器是adam
1 | |
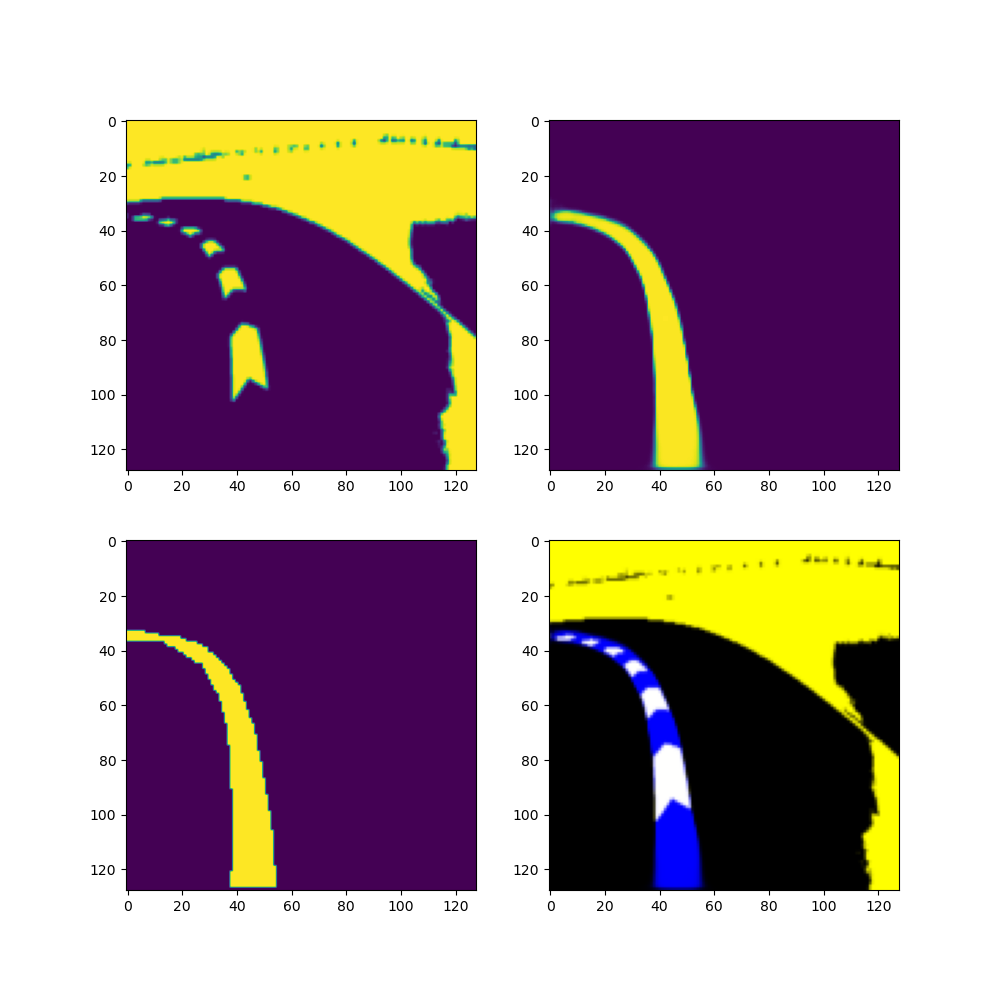
验证
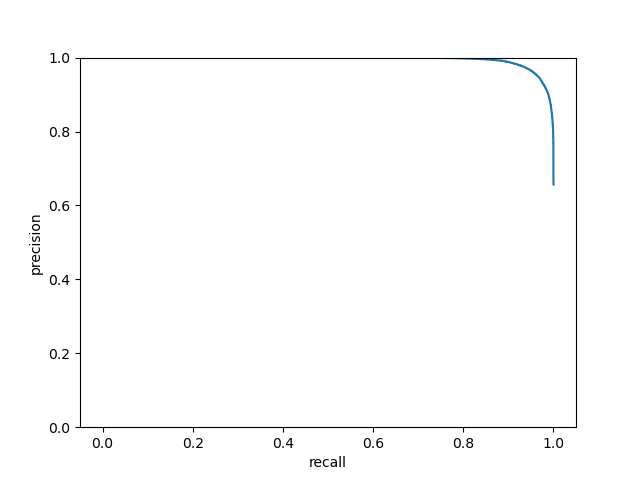
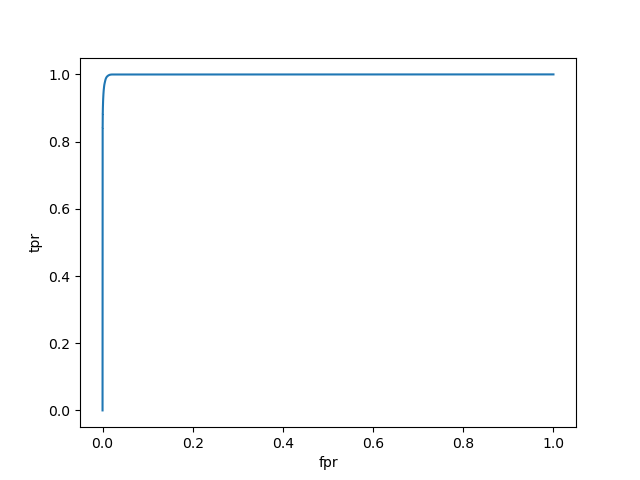
AUC: 0.999587506265614
MF: 0.9579528219690858
AP: 0.9943063698957488
平均时间
验证
auc
精准-召回