本文最后更新于:2022年2月26日 15:13
学习选择
基础:先看的这个,基础操作,用的idle,有些跳了步骤,可能东西比较老(requests、解析(beautiful)、Re、Scrapy)Python数据分析与展示,北京理工大学,中国大学MOOC(慕课) (icourse163.org)
进阶:建议不如直接看这个 ,讲得更细节,用的pycharm,东北老师,讲课老精神了(直接看p51-104,对于基础,补充了Urllib、解析(xpath、jsonpath)、selenium)尚硅谷Python爬虫教程小白零基础速通(含python基础+爬虫案例),哔哩哔哩,bilibili
获取 urllib
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 import urllib.requestimport urllib.parse'https://www.baidu.com/s?wd=' 'User‐Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36' '小野' )print (response.read().decode('utf‐8' ))import urllib.requestimport urllib.parse'http://www.baidu.com/s?' 'name' :'小刚' , 'sex' :'男' ,print (url)'User‐Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36'
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 import urllib.requestimport urllib.parse'https://fanyi.baidu.com/sug' 'user‐agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36' input ('请输入您要查询的单词' )'kw' :keyword'utf‐8' )print (response.read().decode('utf‐8' ))import jsonFalse )print (s)
ajax的get请求(前后端分离的情况,可以拿到json)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 import urllib.requestimport urllib.parsedef create_request (page ):'https://movie.douban.com/j/chart/top_list?type=20&interval_id=100%3A90&action=&' 'User‐Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36' 'start' :(page‐1 )*20 ,'limit' :20 return requestdef get_content (request ):'utf‐8' )return contentdef down_load (page,content ):with open ('douban_' +str (page)+'.json' ,'w' ,encoding='utf‐8' )as fp:if __name__ == '__main__' :int (input ('请输入起始页码' ))int (input ('请输入结束页码' ))for page in range (start_page,end_page+1 ):
异常错误
HTTPError类是URLError类的子类
导入的包urllib.error.HTTPError urllib.error.URLError
http错误:http错误是针对浏览器无法连接到服务器而增加出来的错误提示。引导并告诉浏览者该页是哪里出 了问题。
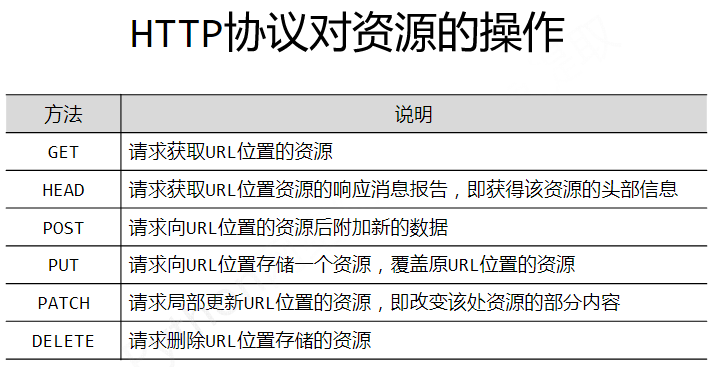
通过urllib发送请求的时候,有可能会发送失败,这个时候如果想让你的代码更加的健壮,可以通过try‐ except进行捕获异常,异常有两类,URLError\HTTPError
cookie登录
cookie 跳过登录
refer 防盗链
handle 定制更高级的请求头(随着业务逻辑的复杂 请求对象的定制已经满足不了我们的需求(动态cookie和代理 不能使用请求对象的定制)
代理服务器(突破自身IP访问限制,访问国外站点。访问一些单位或团体内部资源。提高访问速度。隐藏真实IP)(代理池\快代理)
1 2 3 4 5 6 7 8 9 10 11 12 13 import urllib.request'http://www.baidu.com/s?wd=ip' 'User ‐ Agent' : 'Mozilla / 5.0(Windows NT 10.0;Win64;x64) AppleWebKit / 537.36(KHTML, like Gecko) Chrome / 74.0.3729.169Safari / 537.36' 'http' :'117.141.155.244:53281' }open (request)'utf‐8' )with open ('daili.html' ,'w' ,encoding='utf‐8' )as fp:
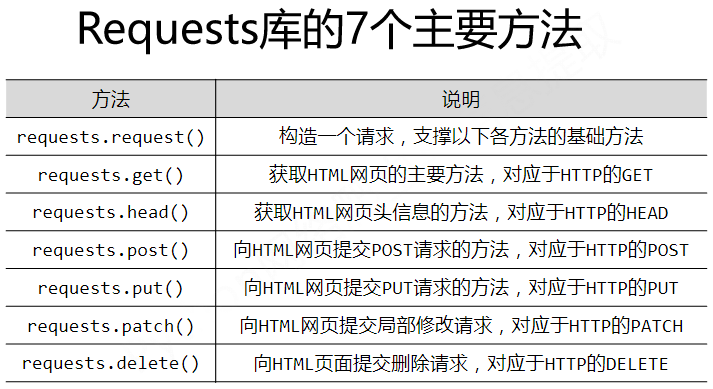
requests
1 2 proxy = {'http' :'219.149.59.250:9797' }
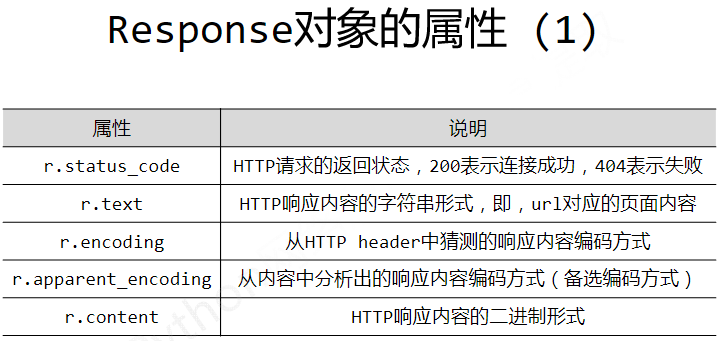
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 import requestsdef getHTMLText (url ):try :30 )return r.textexcept :return "产生异常" if __name__ == "__main__" :"http://www.baidu.com" print (getHTMLText(url))import requests"https://www.amazon.cn/gp/product/B01M8L5Z3Y" try :'user-agent' :'Mozilla/5.0' }print (r.text[1000 :2000 ])except :print ("爬取失败" )import requests"Python" 'http://www.baidu.com/s' try :'wd' : 'keyword' }print (r.status_code)print (r.request.url)print (len (r.text))except :print ("爬取失败" )import requestsimport os"http://xwzx.cumt.edu.cn/_upload/article/images/2f/99/d44299934d00afe8f03684d5c59b/f682d3bc-972c-4d5a-9542-c52e0b72032f.jpg" "D://pics//" '/' )[-1 ]try :if not os.path.exists(root):if not os.path.exists(path):with open (path, 'wb' ) as f:print ("文件保存成功" )else :print ("文件已存在" )except :print ("爬取失败" )import requests"https://ipchaxun.com/" try :'202.204.80.112' )print (r.text[-500 :])except :print ("爬取失败" )
解析 xpath
xpath基本语法
路径查询
//:查找所有子孙节点,不考虑层级关系
/ :找直接子节点
谓词查询
//div[@id]
//div[@id=”maincontent”]
属性查询
//@class
模糊查询
//div[contains(@id, “he”)]
//div[starts‐with(@id, “he”)]
内容查询
//div/h1/text()
逻辑运算
//div[@id=”head” and @class=”s_down”]
//title | //price (其实这是列表的用法)
1 2 3 4 5 6 from lxml import etree'XX.html' )'utf‐8' )
jsonpath 教程连接(http://blog.csdn.net/luxideyao/article/details/77802389)
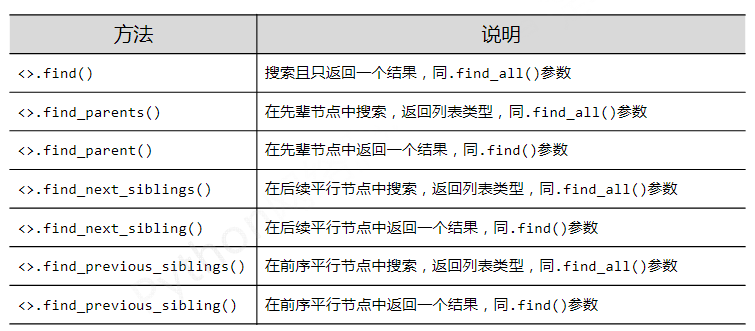
Beautiful Soup
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 import requestsfrom bs4 import BeautifulSoupimport bs4def getHTMLText (url ):try :30 )return r.textexcept :return "" def fillUnivList (ulist, html ):"html.parser" )for tr in soup.find('tbody' ).children:if isinstance (tr, bs4.element.Tag):'td' )0 ].string, tds[1 ].string, tds[3 ].string])def printUnivList (ulist, num ):"{0:^10}\t{1:{3}^10}\t{2:^10}" print (tplt.format ("排名" ,"学校名称" ,"总分" ,chr (12288 )))for i in range (num):print (tplt.format (u[0 ],u[1 ],u[2 ],chr (12288 )))def main ():'https://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html' 20 )
Re
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 import requestsimport redef getHTMLText (url ):try :'user-agent' :'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.99 Safari/537.36 Edg/97.0.1072.76' ,'Cookie' :'【去审查元素自己看看】' 30 , headers=kv)return r.textexcept :print ("getHTMLText" )return "" def parsePage (ilt, html ):try :r'\"view_price\"\:\"[\d\.]*\"' ,html)r'\"raw_title\"\:\".*?\"' ,html)for i in range (len (plt)):eval (plt[i].split(':' )[1 ])eval (tlt[i].split(':' )[1 ])except :print ("parsePage" )def printGoodsList (ilt ):"{:4}\t{:8}\t{:16}" print (tplt.format ("序号" , "价格" , "商品名称" ))0 for g in ilt:1 print (tplt.format (count, g[0 ], g[1 ]))'书包' 3 'https://s.taobao.com/search?q=' + goodsfor i in range (depth):try :'&s=' + str (44 *i)except :continue
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 import requestsfrom bs4 import BeautifulSoupimport tracebackimport redef getHTMLText (url, code="utf-8" ):try :return r.textexcept :return "" def getStockList (lst, stockURL ):"GB2312" )'html.parser' ) 'a' )for i in a:try :'href' ]r"[s][hz]\d{6}" , href)[0 ])except :continue def getStockInfo (lst, stockURL, fpath ):0 for stock in lst:".html" try :if html=="" :continue 'html.parser' )'div' ,attrs={'class' :'stock-bets' })'class' :'bets-name' })[0 ]'股票名称' : name.text.split()[0 ]})'dt' )'dd' )for i in range (len (keyList)):with open (fpath, 'a' , encoding='utf-8' ) as f:str (infoDict) + '\n' )1 print ("\r当前进度: {:.2f}%" .format (count*100 /len (lst)),end="" )except :1 print ("\r当前进度: {:.2f}%" .format (count*100 /len (lst)),end="" )continue def main ():'https://quote.eastmoney.com/stocklist.html' 'https://gupiao.baidu.com/stock/' 'D:/BaiduStockInfo.txt'
python爬取淘宝商品信息&requests.get()和网页源代码不一致_jzj_c_love的博客-CSDN博客
Selenium
selenium的使用步骤?
导入:from selenium import webdriver
创建谷歌浏览器操作对象: path = 谷歌浏览器驱动文件路径 browser = webdriver.Chrome(path)
访问网址 url = 要访问的网址 browser.get(url)
selenium的元素定位 find_element
访问元素信息
获取元素属性 .get_attribute(‘class’)
获取元素文本 .text
获取标签名 .tag_name
交互
点击:click()
输入:send_keys()
后退操作:browser.back()
前进操作:browser.forword()
模拟JS滚动: js=’document.documentElement.scrollTop=100000’ browser.execute_script(js)
执行js代码 获取网页代码:page_source
退出:browser.quit()
Chrome handless
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 from selenium import webdriverfrom selenium.webdriver.chrome.options import Optionsdef share_browser ():'‐‐headless' )'‐‐disable‐gpu' )r'[---]' return browserfrom handless import share_browser'http://www.baidu.com/' )'handless1.png' )
Scrapy
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 import scrapyfrom scrapy_dangdang_095.items import ScrapyDangdang095Itemclass DangSpider (scrapy.Spider ):'dang' 'category.dangdang.com' ]'http://category.dangdang.com/cp01.01.02.00.00.00.html' ]'http://category.dangdang.com/pg' 1 def parse (self, response ):'//ul[@id="component_59"]/li' )for li in li_list:'.//img/@data-original' ).extract_first()if src:else :'.//img/@src' ).extract_first()'.//img/@alt' ).extract_first()'.//p[@class="price"]/span[1]/text()' ).extract_first()yield bookif self.page < 100 :1 str (self.page) + '-cp01.01.02.00.00.00.html' yield scrapy.Request(url=url,callback=self.parse)
1 2 3 4 5 6 7 class ScrapyDangdang095Item (scrapy.Item ):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 from itemadapter import ItemAdapterclass ScrapyDangdang095Pipeline :def open_spider (self,spider ):open ('book.json' ,'w' ,encoding='utf-8' )def process_item (self, item, spider ):str (item))return itemdef close_spider (self,spider ):import urllib.requestclass DangDangDownloadPipeline :def process_item (self, item, spider ):'http:' + item.get('src' )'./books/' + item.get('name' ) + '.jpg' return item
1 2 3 4 5 6 7 'scrapy_dangdang_095.pipelines.ScrapyDangdang095Pipeline' : 300 ,'scrapy_dangdang_095.pipelines.DangDangDownloadPipeline' :301